A Ferguson Twitter Archive
If you are interested in an update about where/how to get the data after reading this see here.
Much has been written about the significance of Twitter as the recent events in Ferguson echoed round the Web, the country, and the world. I happened to be at the Society of American Archivists meeting 5 days after Michael Brown was killed. During our panel discussion someone asked about the role that archivists should play in documenting the event.
There was wide agreement that Ferguson was a painful reminder of the type of event that archivists working to “interrogate the role of power, ethics, and regulation in information systems” should be documenting. But what to do? Unfortunately we didn’t have time to really discuss exactly how this agreement translated into action.
Fortunately the very next day the Archive-It service run by the Internet Archive announced that they were collecting seed URLs for a Web archive related to Ferguson. It was only then, after also having finally read Zeynep Tufekci’s terrific Medium post, that I slapped myself on the forehead … of course, we should try to archive the tweets. Ideally there would be a “we” but the reality was it was just “me”. Still, it seemed worth seeing how much I could get done.
twarc
I had some previous experience archiving tweets related to Aaron Swartz using Twitter’s search API. (Full disclosure: I also worked on the Twitter archiving project at the Library of Congress, but did not use any of that code or data then, or now.) I wrote a small Python command line program named twarc (a portmanteau for Twitter Archive), to help manage the archiving.
You give twarc a search query term, and it will plod through the search results, in reverse chronological order (the order that they are returned in), while handling quota limits, and writing out line-oriented-json, where each line is a complete tweet. It worked quite well to collect 630,000 tweets mentioning “aaronsw”, but I was starting late out of the gate, 6 days after the events in Ferguson began. One downside to twarc is it is completely dependent on Twitter’s search API, which only returns results for the past week or so. You can search back further in Twitter’s Web app, but that seems to be a privileged client. I can’t seem to convince the API to keep going back in time past a week or so.
So time was of the essence. I started up twarc searching for all tweets
that mention ferguson, but quickly realized that the volume of
tweets, and the order of the search results meant that I wouldn’t be
able to retrieve the earliest tweets. So I tried to guesstimate a
Twitter ID far enough back in time to use with twarc’s
–max_id parameter to limit the initial query to tweets
before that point in time. Doing this I was able to get back to
2014-08-10 22:44:43 – most of August 9th and 10th had slipped out of the
window. I used a similar technique of guessing a ID further in the
future in combination with the –since_id parameter to start
collecting from where that snapshot left off. This resulted in a bit of
a fragmented record, which you can see visualized (sort of below):
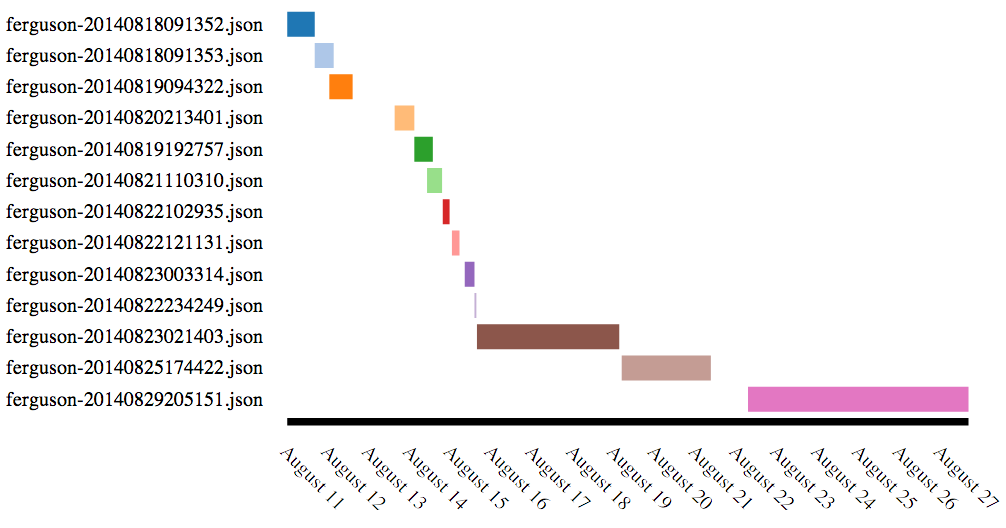
In the end I collected 13,480,000 tweets (63G of JSON) between August 10th and August 27th. There were some gaps because of mismanagement of twarc, and the data just moving too fast for me to recover from them: most of August 13th is missing, as well as part of August 22nd. I’ll know better next time how to manage this higher volume collection.
Apart from the data, a nice side effect of this work is that I fixed a socket timeout error in twarc that I hadn’t noticed before. I also refactored it a bit so I could use it programmatically like a library instead of only as a command line tool. This allowed me to write a program to archive the tweets, incrementing the max_id and since_id values automatically. The longer continuous crawls near the end are the result of using twarc more as a library from another program.
Bag of Tweets
To try to arrange/package the data a bit I decided to order all the tweets by tweet id, and split them up into gzipped files of 1 million tweets each. Sorting 13 million tweets was pretty easy using leveldb. I first loaded all 16 million tweets into the db, using the tweet id as the key, and the JSON string as the value.
import json
import leveldb
import fileinput
db = leveldb.LevelDB('./tweets.db')
for line in fileinput.input():
tweet = json.loads(line)
db.Put(tweet['id_str'], line)
This took almost 2 hours on a medium ec2 instance. Then I walked the leveldb index, writing out the JSON as I went, which took 35 minutes:
import leveldb
db = leveldb.LevelDB('./tweets.db')
for k, v in db.RangeIter(None, include_value=True):
print v,
After splitting them up into 1 million line files with cut and gzipping them I put them in a Bag and uploaded it to s3 (8.5G).
I am planning on trying to extract URLs from the tweets to try to come up with a list of seed URLs for the Archive-It crawl. If you have ideas of how to use it definitely get in touch. I haven’t decided yet if/where to host the data publicly. If you have ideas please get in touch about that too!