Hacking O'Reilly RDFa
I recently learned from Ivan Herman’s blog that O’Reilly has begun publishing RDFa in their online catalog of books. So if you go and install the RDFa Highlight bookmarklet and then visit a page like this and click on the bookmarklet you’ll see something like:
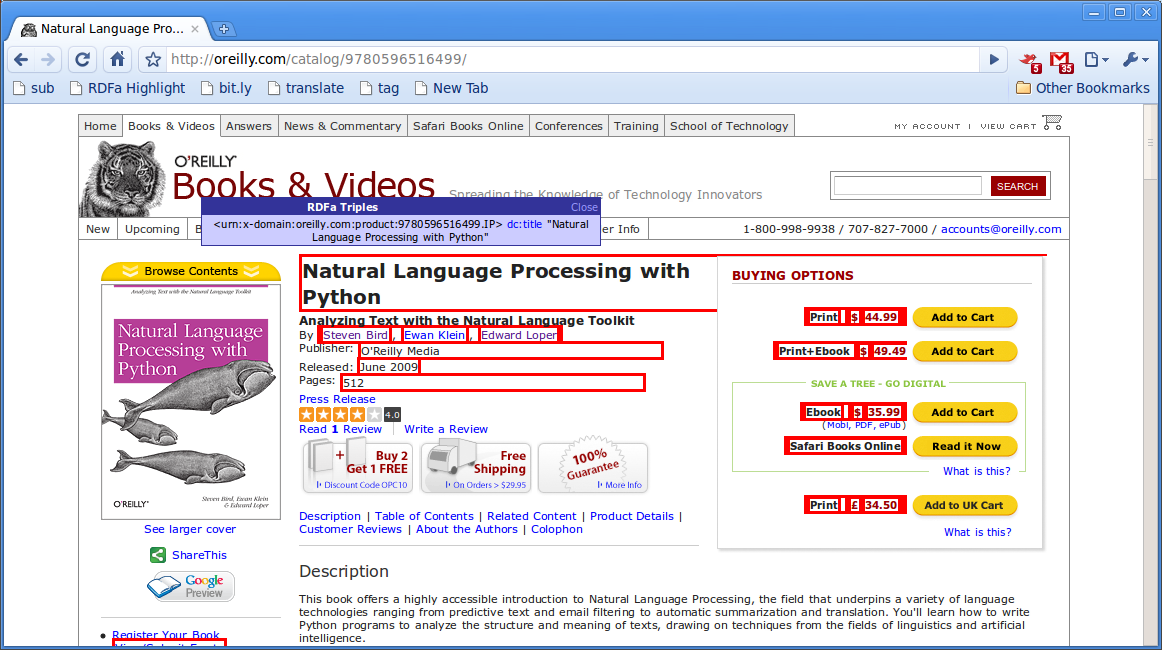
Those red boxes you see are graphical depictions of where metadata can be found interleaved in the HTML. In my screenshot you can maybe barely see an assertion involving the title being displayed:
<urn:x-domain:oreilly.com:product:9780596516499.IP> dc:title "Natural Language Processing with Python"
But there is actually quite a lot of metadata hiding in the page, which can be found by running the page through the RDFa Distiller (quickly skim over this if your eyes glaze over when you see Turtle):
@prefix dc: <http://purl.org/dc/terms/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix frbr: <http://vocab.org/frbr/core#> .
@prefix gr: <http://purl.org/goodrelations/v1#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<urn:x-domain:oreilly.com:product:9780596516499.IP> a frbr:Expression ;
dc:creator <urn:x-domain:oreilly.com:agent:pdb:3343>, <urn:x-domain:oreilly.com:agent:pdb:3501>, <urn:x-domain:oreilly.com:agent:pdb:3502> ;
dc:issued "2009-06-12"^^xsd:dateTime ;
dc:publisher "O'Reilly Media"@en ;
dc:title "Natural Language Processing with Python"@en ;
frbr:embodiment <urn:x-domain:oreilly.com:product:9780596516499.BOOK>, <urn:x-domain:oreilly.com:product:9780596803346.SAF>, <urn:x-domain:oreilly.com:product:9780596803391.EBOOK> .
<http://customer.wileyeurope.com/CGI-BIN/lansaweb?procfun+shopcart+shcfn01+funcparms+parmisbn(a0130):9780596516499+parmqty(p0050):1+parmurl(l0560):http://oreilly.com/store/> a gr:Offering ;
gr:includesObject
[ a gr:TypeAndQuantityNode ;
gr:ammountOfThisGood "1"^^xsd:float ;
gr:hasPriceSpecification
[ a gr:UnitPriceSpecification ;
gr:hasCurrency "GBP"@en ;
gr:hasCurrencyValue "34.50"^^xsd:float
] ;
gr:typeOfGood <urn:x-domain:oreilly.com:product:9780596516499.BOOK>
] .
<http://my.safaribooksonline.com/9780596803346> a gr:Offering ;
gr:includesObject
[ a gr:TypeAndQuantityNode ;
gr:ammountOfThisGood "1"^^xsd:float ;
gr:typeOfGood <urn:x-domain:oreilly.com:product:9780596803346.SAF>
] .
<https://epoch.oreilly.com/shop/cart.orm?p=BUNDLE&prod=9780596516499.BOOK&prod=9780596803391.EBOOK&bundle=1&retUrl=http%3A%252F%252Foreilly.com%252Fstore%252F> a gr:Offering ;
gr:includesObject
[ a gr:TypeAndQuantityNode ;
gr:ammountOfThisGood "1"^^xsd:float ;
gr:includesObject
[ a gr:TypeAndQuantityNode ;
gr:ammountOfThisGood "1"^^xsd:float ;
gr:hasPriceSpecification
[ a gr:UnitPriceSpecification ;
gr:hasCurrency "None"@en ;
gr:hasCurrencyValue "49.49"^^xsd:float
] ;
gr:typeOfGood <urn:x-domain:oreilly.com:product:9780596803391.EBOOK>
] ;
gr:typeOfGood <urn:x-domain:oreilly.com:product:9780596516499.BOOK>
] .
<https://epoch.oreilly.com/shop/cart.orm?prod=9780596516499.BOOK> a gr:Offering ;
gr:includesObject
[ a gr:TypeAndQuantityNode ;
gr:ammountOfThisGood "1"^^xsd:float ;
gr:hasPriceSpecification
[ a gr:UnitPriceSpecification ;
gr:hasCurrency "USD"@en ;
gr:hasCurrencyValue "44.99"^^xsd:float
] ;
gr:typeOfGood <urn:x-domain:oreilly.com:product:9780596516499.BOOK>
] .
<https://epoch.oreilly.com/shop/cart.orm?prod=9780596803391.EBOOK> a gr:Offering ;
gr:includesObject
[ a gr:TypeAndQuantityNode ;
gr:ammountOfThisGood "1"^^xsd:float ;
gr:hasPriceSpecification
[ a gr:UnitPriceSpecification ;
gr:hasCurrency "USD"@en ;
gr:hasCurrencyValue "35.99"^^xsd:float
] ;
gr:typeOfGood <urn:x-domain:oreilly.com:product:9780596803391.EBOOK>
] .
<urn:x-domain:oreilly.com:agent:pdb:3343> a foaf:Person ;
foaf:homepage <http://www.oreillynet.com/pub/au/3614> ;
foaf:name "Steven Bird"@en .
<urn:x-domain:oreilly.com:agent:pdb:3501> a foaf:Person ;
foaf:homepage <http://www.oreillynet.com/pub/au/3615> ;
foaf:name "Ewan Klein"@en .
<urn:x-domain:oreilly.com:agent:pdb:3502> a foaf:Person ;
foaf:homepage <http://www.oreillynet.com/pub/au/3616> ;
foaf:name "Edward Loper"@en .
<urn:x-domain:oreilly.com:product:9780596803346.SAF> a frbr:Manifestation ;
dc:type <http://purl.oreilly.com/product-types/SAF> .
<urn:x-domain:oreilly.com:product:9780596803391.EBOOK> a frbr:Manifestation ;
dc:identifier <urn:isbn:9780596803391> ;
dc:issued "2009-06-12"^^xsd:dateTime ;
dc:type <http://purl.oreilly.com/product-types/EBOOK> .
<urn:x-domain:oreilly.com:product:9780596516499.BOOK> a frbr:Manifestation ;
dc:extent """512"""@en ;
dc:identifier <urn:isbn:9780596516499> ;
dc:issued "2009-06-19"^^xsd:dateTime ;
dc:type <http://purl.oreilly.com/product-types/BOOK> .
So that’s a lot of data. The nice thing about rdf is that you can look at the vocabularies that are being used to get an idea of the rough shape of the underlying data. Just looking at the namespace prefixes we can see that O’Reilly has chosen to use the following vocabularies:
- Dublin Core Terms: for indicating the publisher, title, authors, issue date and identifiers for a book
- Friend of a Friend (FOAF): for modeling authors as People
- Functional Requirements for Bibliographic Records (FRBR): for relating a particular book (Expression) to its various Manifestations of the title: ebook, printed book
- Good Relations: for making pricing information available
I was curious so I wrote a little crawler (41 lines of Python+rdflib) to collect all the metadata from the O’Reilly Catalog pages. Yes all the pages! It ended up pulling down 92,101 triples.
A nice side effect of having the data as a big ntriples file is you can do unix pipe tricks with sort, cut, uniq like this to get some ballpark numbers on what types of resources are in the rdf graph:
ed@curry:~/Projects/oreilly-crawler$ rdfsum catalog.nt 6803 <http://purl.org/goodrelations/v1#TypeAndQuantityNode> 5861 <http://purl.org/goodrelations/v1#Offering> 4564 <http://purl.org/goodrelations/v1#UnitPriceSpecification> 4065 <http://vocab.org/frbr/core#Manifestation> 2100 <http://vocab.org/frbr/core#Expression> 2023 <http://xmlns.com/foaf/0.1/Person>
Another nice thing about pulling the RDFa down with rdflib is you end up with a little berkeleydb triple store which you can query with SPARQL, say to pull out all the authors and titles:
SELECT ?title ?author
WHERE {
?title_uri dct:title ?title .
?title_uri dct:creator ?author_uri .
?author_uri foaf:name ?author .
}
And adding a little bit of networkx judo you can get an xmas-friendly graph of authors (the green dots are books and the red ones are authors ; I limited author labels to authors who had written more than 2 books).
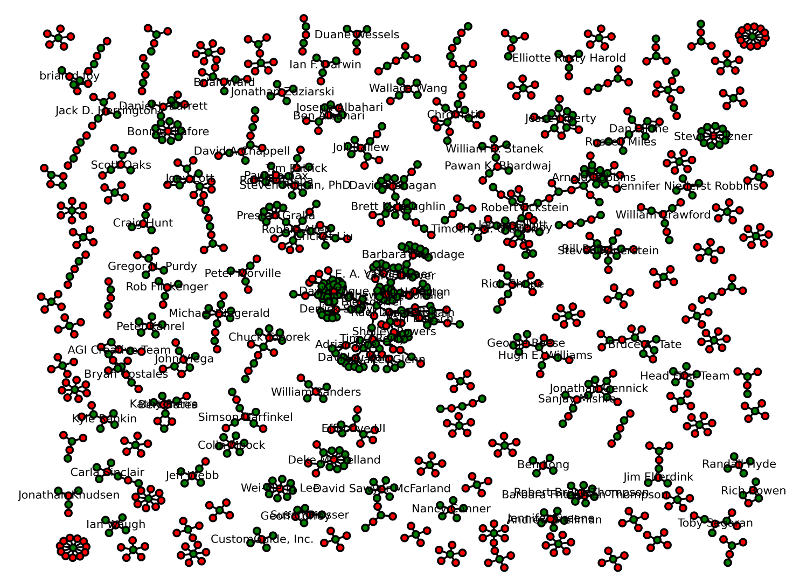
Admittedly this is not very readable, but I imagine someone with more network visualization skillz could do something nicer in short order. There’s a lot that could be done with the data. This exercise was mainly just to demonstrate how layering some new stuff into your HTML can really open up doors for how people use your website. Clearly O’Reilly did some deep thinking about what data they had, and what vocabularies they wanted to model it with. But once they’d done that they probably just had to go add 50 lines to an HTML template somewhere, and it was published (props to David Brunton for this turn of phrase). It’s a really good sign that a tech publisher with the stature of O’Reilly is giving this method of data publishing a try.
My only suggestion (for anyone at O’Reilly who might be reading) would be that it would be nice if they used HTTP URLs instead of URNs for People, Works and Expressions. I understand why they did it: using URNs eases deployment somewhat since you don’t have to worry about httpRange-14 stuff. But I think they could easily use a hash URI instead of an URN, and make it easy for people to link to their stuff in other data. The Cool URIs For the Semantic Web has some other patterns they might want to consider, but simply adding a hash to their existing page URIs should do the trick. So for example, consider if OpenLibrary wanted to link their notion of of a book to O’Reilly’s notion of a book with owl:sameAs. If they used they URN they’d have:
<http://openlibrary.org/b/OL23978297M> owl:sameAs <urn:x-domain:oreilly.com:product:9780596516499.IP> .
but if O’Reilly identified their expressions with a URL they would enable something like:
<http://openlibrary.org/b/OL23978297M> owl:sameAs <http://oreilly.com/catalog/9780596516499#expression> .
This may seem like a minor point, but it’s really important to be able to follow your nose on the web–particularly in Linked Data. If a piece of software ran across the O’Reilly URL in a chunk of OpenLibrary RDF, the program could HTTP GET it, and learn more stuff about the book. But if it got the URN it wouldn’t really know how to fetch a representation for that resource without some special case logic that mapped the URN to a URL. There is a reason why Tim Berners-Lee included the following as the second of his design principles for Linked Data:
Use HTTP URIs so that people can look up those names.
Anyhow, hats off to O’Reilly for putting RDFa into practice. I hope the rest of the publishing (and library world) take note. If you are looking to learn more about RDFa Ben Adida and Mark Birbeck’s RDFa Primer: Bridging the Human and Data Webs is a really nice intro.