The Web as a Preservation Medium
This is the text of a talk I gave at the (wonderful) National Digital Forum in Wellington, New Zealand on November 27th, 2013. You can also find my slides here, and the video here. If you do happen to watch the video, you’ll probably notice I spent more time thinking about the text than I did practicing my talk.

Hi there. Thanks for inviting me to NDF 2013, it is a real treat and honor to be here. I’d like to dedicate this talk to Aaron Swartz. Aaron cared deeply about the Web. In a heartbreaking way I think he may have cared more than he was able to. I’m not going to talk much about Aaron specifically, but his work and spirit underly pretty much everything I’m going to talk about today. If there is one message that I would like you to get from my talk today it’s that we need to work together as professionals to care for the Web in the same way Aaron cared for it.
Next year it will be 25 years since Tim Berners-Lee wrote his proposal to build the World Wide Web. I’ve spent almost half of my life working with the technology of the Web. The Web has been good to me. I imagine it has been good to you as well. I highly doubt I would be standing here talking to you today if it wasn’t for the Web. Perhaps the National Digital Forum would not exist, if it was not for the Web. Sometimes I wonder if we need the Web to continue to survive as a species. It’s certainly hard for my kids to imagine a world without the Web. In a way it’s even hard for me to remember it. This is the way of media, slipping into the very fabric of experience. Today I’d like to talk to you about what it means to think about the Web as a preservation medium.

Medium and preservation are some pretty fuzzy, heavy words, and I’m not going to try to pin them down too much. We know from Marshall McLuhan that the medium is the message. I like this definition because it disorients more than it defines. McLuhan reminds us of how we are shaped by our media, just as we shape new forms of media. In her book Always Already New, Lisa Gitelman offers up a definition of media that gives us a bit more to chew on:
I define media as socially realized structures of communication, where structures include both technological forms and their associated protocols, and where communication is a cultural practice, a ritualized collocation of different people on the same mental map, sharing or engaged with popular ontologies of representation.
I like Gitelman’s definition because it emphasizes how important the social dimension is to our understanding of media. The affordances of media, how media are used by people to do things, and how media does things to us, are just as important as the technical qualities of media. In the spirit of Latour she casts media as a fully fledged actor, not as some innocent bystander or tool to be used by the real and only actors, namely people.
When Matthew Oliver wrote to invite me to speak here he said that in recent years NDF had focused on the museum, and that there was some revival of interest in libraries. The spread of the Web has unified the cultural heritage sector, showing how much libraries, archives and museums have in common, despite their use of subtly different words to describe what they do. I think preservation is a similar unifying concept. We all share an interest in keeping the stuff (paintings, sculptures, books, manuscripts, etc) around for another day, so that someone will be able to see it, use it, cite it, re-interpret it.
Unlike the traditional media we care for, the Web confounds us all equally. We’ve traditionally thought of preservation and access as different activities, that often were at odds with each other. Matthew Kirschenbaum dispels this notion:
… the preservation of digital objects is logically inseparable from the act of their creation – the lag between creation and preservation collapses completely, since a digital object may only ever be said to be preserved if it is accessible, and each individual access creates the object anew. The .txtual Condition
Or, as my colleague David Brunton has said, in a McLuhan-esque way:
Digital preservation is access…in the future.
The underlying implication here is that if you are not providing meaningful access in the present to digital content, then you are not preserving it.
In light of these loose definitions I’m going to spend the rest of the time exploring what the Web means as a preservation medium by telling some stories. I’m hoping that they will help illuminate what preservation means in the context of the Web. By the end I hope to convince you of two things: the Web needs us to care for it, and more importantly, we need the Web to do our jobs effectively. For those of you who don’t need convincing about either of these points, I hope to give you a slightly different lens for looking at preservation and the Web. It’s a hopeful and humanistic lens, that is informed by thinking about the Web as an archive. But more on that later.
Everything is Broken
Even the casual user of the Web has run across the problem of the 404 Not Found. In a recent survey of Web citations found in Thompson Reuter’s Web of Science, Hennessey and Ge found that only 69% of the URLs were still available, and the median lifetime for a URL was 9.3 years. The Internet Archive had archived 62% of these URLs. In a similar study of URLs found in recent papers in the popular arXiv pre-print repository Sanderson, Phillips and Van de Sompel found that of the 144,087 unique URLs referenced in papers, only 70% were still available and of these, 45% were not archived in the Internet Archive, Web Citation, the Library of Congress or the UK National Archive.
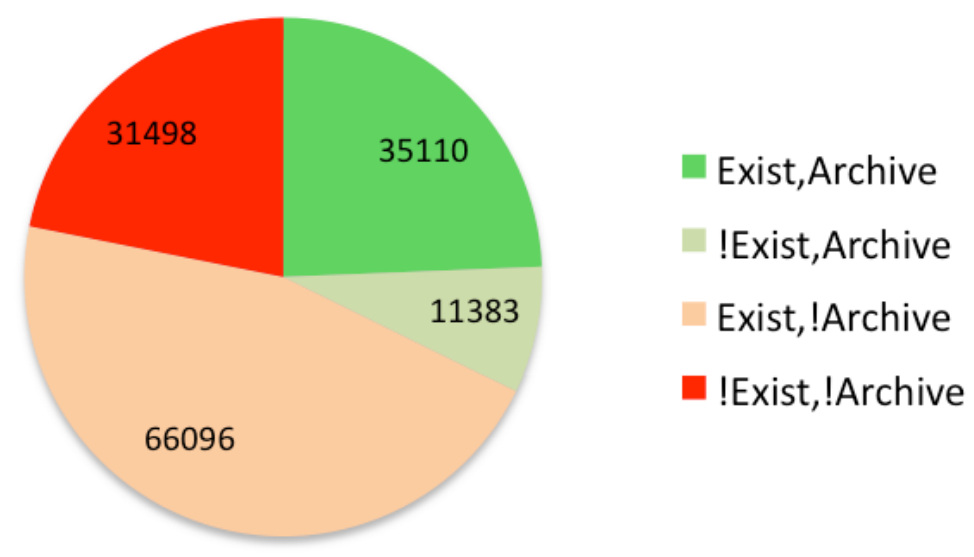
Bear in mind, this isn’t the World Wild Web of dot com bubbles, failed business plans, and pivots we’re talking about. These URLs were found in a small pocket of the Web for academic research, a body of literature that is built on a foundation of citation, and written by practitioners whose very livelihood is dependent on how they are cited by others.
A few months ago the 404 made mainstream news in the US when Adam Liptak’s story In Supreme Court Opinions, Web Links to Nowhere broke in the New York Times. Liptak’s story spotlighted a recent study by Zittrain and Albert which found that 50% of links in United States Supreme Court opinions were broken. As its name suggests, the Supreme Court is the highest federal court in the United States…it is the final interpreter of our Constitution. These opinions in turn document the decisions of the Supreme Court, and have increasingly referenced content on the Web for context, which becomes important later for interpretation. 50% of the URLs found in the opinions suffered from what the authors call reference rot. Reference rot includes situations of link rot (404 Not Found and other HTTP level errors), but it also includes when the URL appears to technically work, but the content that was cited is no longer available. The point was dramatically and humorously illustrated by the New York Times since someone had bought one of the lapsed domains and put up a message for Justice Alito:

Zittrain and Albert propose a new web archiving project called perma.cc, which relies on libraries to select web pages and websites that need to be archived. As proposed perma.cc would be similar in principle to WebCite, which is built around submission of URLs by scholars. But WebCite’s future is uncertain due to a fund drive to raise money to support its operation. perma.cc also has the potential to offer a governance structure similar to how cultural heritage organizations support the Internet Archive in their crawls of the Web.

Internet Archive was started by Brewster Kahle in 1996. It now contains 366 billion web pages or captures (not unique URLs). In 2008 Google Engineers reported that their index contained 1 trillion unique URLs. That’s 5 years ago now. If we assume it hasn’t grown since then, and overlook the fact that there are often multiple captures of a given URL over time, Internet Archive contains about 37% of the Web. This is overly generous since the Web has almost certainly grown in the past 5 years, and we’re comparing apples and oranges, web captures to unique URLs.
Of course, it’s not really fair (or prudent) to put the weight of preserving the Web on one institution. So thankfully, the Internet Archive isn’t alone. The International Internet Preservation Consortium is a member organization made up of national libraries, universities, and other organizations that do Web archiving. The National Library of New Zealand is a member, and has its own Web archive. According to the list of Web archiving initiatives Wikipedia article the archive is comprised of 346 million URLs. Perhaps someone in the audience has a rough idea of how big this is relative to the size of the Kiwi Web. It’s a bit of a technical problem even to identify national boundaries on the Web. Since the National Library of New Zealand Act of 2003, the National Library has been authorized to crawl the New Zealand portion of the Web. In this regard, New Zealand is light years ahead of the United States, which still is required by law to ask for permission to collect selected, non-governmental websites.
Protocols and tools for sharing the size and makeup of these IIPC collections are still lacking, but the Memento project spurred on some possible approaches out of necessity. For the Memento prototype to work they needed to collect the URL/timestamp combinations for all archived webpages. This turned out to be difficult both for the archive to share, and to aggregate in one place efficiently–and the moment it was done it was already out of date. David Rosenthal has some interesting ideas for aggregators to collect summary data from web archives, which is used to instead provide hints about where a given URL may be archived. Hopefully we’ll see some development in this area, as it’s increasingly important that Web archives do collection development more closely, to encourage diversity of approaches, and ensure that one isn’t a single point of failure.
Even when you consider the work of the International Internet Preservation Consortium, which adds roughly 75 billion URLs (also not unique) we still are only seeing 44% of the Web being archived. And of course this is a very generous guesstimate, since the 366 billion Internet Archive captures are not unique URLs: e.g. a given URL like the BBC homepage has been fetched 13,863 times between December 21, 1996 and November 14, 2013. And there is almost certainly overlap between the various IIPC web archives and the Internet Archive.
The Archival Sliver
I am citing these statistics not to say the job of archiving the Web is impossible, or a waste of resources. Much to the contrary. I raise it here to introduce one of the archival lenses I want to encourage you to look at Web preservation through: Verne Harris’ notion of the archival sliver. Harris is a South African archivist, writer and director of the Archive at the Nelson Mandela Centre of Memory. He participated in the transformation of South Africa’s apartheid public records system, and got to see up close how the contents of archives are shaped by the power structures in which they are embedded. Harris’ ideas have a distinctly post-modern flavor, and contrast with positivist theories of the archive that assert that the archive’s goal is to reflect reality.
Even if archivists in a particular country were to preserve every record generated throughout the land, they would still have only a sliver of a window into that country’s experience. But of course in practice, this record universum is substantially reduced through deliberate and inadvertent destruction by records creators and managers, leaving a sliver of a sliver from which archivists select what they will preserve. And they do not preserve much.
I like Harris’ notion of the archival sliver, because he doesn’t see it as a cause for despair, but rather as a reason to celebrate the role that this archival sliver has in the process of social memory, and the archivist who tends to it.
The archival record … is best understood as a sliver of a sliver of a sliver of a window into process. It is a fragile thing, an enchanted thing, defined not by its connections to “reality,” but by its open-ended layerings of construction and reconstruction. Far from constituting the solid structure around which imagination can play, it is itself the stuff of imagination.
The First URL
So instead of considering the preservation of billions of URLs, lets change tack a bit and take a look at the preservation of one, namely the first URL.
http://info.cern.ch/hypertext/WWW/TheProject.html
On April 30th, 1993 CERN made (in hindsight) the momentous decision to freely-release the Web technology software that Tim Berners-Lee, Ari Luotonen and Henrik Nielsen created for making the first website. But 20 years later, that website was no longer available. To celebrate the 20th anniversary of the software release Dan Noyes from CERN led a project to bring the original website back online, at the same address using a completely different software stack. The original content was collected from a variety of places: some from the W3C, some from a 1999 backup of Tim Berners-Lee’s NeXT. While the content is how it looked then, the resurrected website isn’t running the original Web server software, it’s running a modern version of Apache.

CERN also hosted a group of 11 volunteer developers to spend 2 days coding at CERN (expenses paid) to recreate the experience of using the line mode browser (LMB). The LMB allowed users with an Internet connection to use the Web without having to install any software: they could simply telnet to info.cern.ch and start browsing the emerging Web using their terminal. These developers created a NodeJS JavaScript application that simulates the experience of using the early Web. You can even use it to navigate to other pages, for example the current World Wide Web Consortium page.
In a lot of ways I think this work illustrates James Governor’s adage:
Applications are like fish, data is like wine. Only one improves with age.
As any old school LISP programmer will tell you, sometimes code is data and data is code. But it is remarkable that this 20 year old HTML still renders just fine in a modern Web browser. This is no accident, but is the result of thoughtful, just-in-time design that encouraged the evolvability, extensibility and customizability of the Web. I think we as a community still have lots to learn from the Web’s example, and lots more to import into our practices. More about HTML in a bit.
Permalinks

Now obviously this sort of attention can’t be paid to all broken URLs on the Web. But it seems like an interesting example of how an archival sliver of the Web was cared for, respected and valued. Despite popular opinion, the care for URLs is not something foreign to the Web. For example lets take a look at the idea of the permalink that was popularized by the blogging community. As you know, a blog is typically a stream of content. In 2000 Paul Bausch at Blogger came up with a way to assign URLs to individual posts in the stream. This practice is so ubiquitous now it’s difficult to see what an innovation it was at the time. As its name implies, the idea of the permalink is that it is stable over time, so that the content can be persistently referenced. Apart from longevity, permalinks have beneficial SEO characteristics: the more that people link to the page over time, the higher its PageRank, and the more people who will find it in search results.

A couple years before the blogging community started talking about permalinks, Tim Berners-Lee wrote a short W3C design note entitled Cool URIs Don’t Change. In it he provides some (often humorously snarky) advice for people to think about their URLs, and namespaces with an eye to their future. One of Berners-Lee’s great insights was to allow any HTML document to link to any other HTML document, without permission. This decision allowed the Web to grow in a decentralized fashion. It also means that links can break when pages drift apart, and move to new locations, or disappear. But just because a link can break doesn’t mean that it must break.

The idea of Cool URIs saw new life in 2006 when Leo Sauerman and Richard Cyganiak began work on Cool URIs for the Semantic Web, which became a seminal document for the Linked Data movement. Their key insight was that identity (URLs) matters on the Web, especially when you are trying to create a distributed database like the Semantic Web.
Call them permalinks or Cool URIs, the idea is the same. Well managed websites will be rewarded by more links to their content, improved SEO, and ultimately more users. But most of all they will be rewarded by a better understanding of what they are putting on the Web. Organizations, particularly cultural heritage organization should take note – especially their “architects”. Libraries, archives and museums need to become regions of stability on the Web, where URLs don’t capriciously fail because some exhibit is over, or some content management system is swapped out for another. This doesn’t mean content can’t change, move or even be deleted. It just means we need to know when we are doing it, and say where something has moved, or say that what was once there is now gone. If we can’t do it, the websites that do will become the new libraries and archives of the Web.
Community

Clearly there is a space between large scale projects to archive the entire Web, and efforts to curate a particular website. Consider the work of ArchiveTeam, a volunteer organization formed in 2009 that keeps an eye on when websites are in danger of, actually are, closing their doors and shutting down. Using their wiki, IRC chatrooms, and software tools they have built up a community of practice around archiving websites, which have included some 60 sites, such as Geocities and Friendster. They maintain a page called the Death Watch where they list sites that are dying (pining for the fjords), or in danger of dying (pre-emptive alarm bells). These activist archivists run something called the Warrior which is a virtual appliance you can install on a workstation, which gets instructions from the Archive Team tracker about which URLs to download, and coordinates the collection. The tracker then collects statistics, that allow participants to see how much they have contributed relative to others. The collected data is then packed up as WARC files and delivered to the Internet Archive where it is reviewed by an adminstrator, and added to their Web collection.
ArchiveTeam is a labor of love for its creator Jason Scott Sadofsky (aka Jason Scott) who is himself an accomplished documenter of computing history, with films such as BBS: The Documentary (early bulletin board systems), Get Lamp (interactive fiction) and DEFCON: The Documentary. Apart from mobilizing action, his regular talks have raised awareness about the impermanence on the Web, and have connected with other like minded Web archivists in a way that traditional digital preservation projects have struggled to. I suspect that this self-described “collective of rogue archivists, programmers, writers and loudmouths dedicated to saving our digital heritage” is the shape of things to come for the profession. ArchiveTeam are not the only activists archiving parts of the Web, lets take a look at a few more examples.
Earlier this year Google announced that they were pulling Google Reader offline. This caused much grief and anger to be vented from the blogging community…but it spurred one person into action. Mihai Parparita was an engineer who helped create Google Reader at Google, but he no longer worked there, and wanted to do something to help people retain both their data and the experience of Google Reader. Because he felt that the snapshots of data provided weren’t complete, he quickly put together a project ReaderIsDead, which is also available on GitHub. ReaderIsDead is actually a collection of different tools: one for pulling down your personal Reader data from Google while the Google Reader servers were still alive, and a simple web application called ZombieReader that serves that data up, for when the Google Reader servers actually went dead. Mihai put his knowledge of how the Google Reader talked to backend Web service APIs to build ZombieReader.
Ordinarily fat client interfaces like Google Reader pose problems for traditional Web archiving tools like Internet Archive’s Heretrix. Fat Web clients are applications that largely run in your browser, using JavaScript. These applications typically talk back to Web service APIs to fetch more data (often JSON) based on interaction in the browser. Web archiving crawlers don’t typically execute JavaScript that is crawled from the Web, and have a hard (if not impossible) time simulating user behavior, which then triggers the calls back to the Web service. And of course the Web Service is what goes dead as well, so even if the Web archive has a snapshot of the requested data, the JavaScript would need to be changed to fetch it. This means the Web archive is left with a largely useless shell.
But in the case of Zombie Reader, the fat client provided a data abstraction that proved to be an excellent way to preserve both the personal data and the user experience of using Google Reader. Mihai was able to use the same HTML, CSS and JavaScript from GoogleReader, but instead of the application talking back to Google’s API he had it talk back to a local Web Service that sat on top of the archived data. Individual users could continue to use their personal archives. ZombieReader became a read-only snapshot of what they were reading on the Web, and their interactions with it. Their sliver of a sliver of a sliver.
Impermanence
Of course .com failures aren’t the only reason why content disappears from the Web. People intentionally remove content from the Web all the time for a variety of reasons. Let’s consider the strange, yet fascinating cases of Mark Pilgrim and Jonathan Gillette. Both were highly prolific software developers, bloggers, authors and well known spokespeople for open source and the Web commons.

Among other things, Mark Pilgrim was very active in the area of feed syndication technology (RSS, Atom). He wrote the feed validator and Universal Feed Parser that makes working with syndicated much easier. He also pushed the boundaries of technical writing by writing Dive Into HTML 5 and Dive Into Python 3 which were published traditionally as books, but also made available on the Web with a CC-BY license. Pilgrim also worked at Google, where he helped promote and evolve the Web with his involvement in the Web Hypertext Application Technology Working Group WHATWG.

Jonathan Gillette, also known as Why the Lucky Stiff or _why, was a prolific writer, cartoonist, artist, and computer programmer who helped popularize the Ruby programming language. His online book Why’s (Poignant) Guide to Ruby introduced people of all ages to the practice of programming with wit and humor that will literally make you laugh out loud as you learn. His projects such like Try Ruby and Hackety Hack! lowered the barriers to getting a working software development environment set up by moving it to the Web. He also wrote a great deal of software such as hpricot for parsing HTML, and the minimalist Web framework camping.
Apart from all these similarities Mark Pilgrim and Jonathan Gillette share something else in common: on October 4, 2011 and August 19, 2009 respectively they both decided to completely delete their online presence from the Web. They committed info-suicide. Their online books, blogs, social media accounts, and github projects were simply removed. No explanations were made, they just blinked out of existence. They are still alive here in the physical world, but they aren’t participating online as they were previously…or at least not using the same personas. I like to think Pilgrim and _why were doing performance art to illustrate the fundamental nature of the Web, its nowness, its fragility, it’s impermanence. As Dan Connolly said once:
The point of the Web arch[itecture] is that it builds the illusion of a shared information space.
If someone decides to turn off a server or delete a website it’s gone for the entire world, the illusion dissolves. Maybe it lives on buried in a Web archive, but it’s previous life out on the Web is over. Or is it?
It’s interesting to see what happened after the info-suicides. Why’s (Poignant) Guide to Ruby was rescued by Mislav Marohnic a software developer living in Croatia. He was able to piece the book back together based on content in the Internet Archive, and put it back online at a new URL, as if nothing had happened. In addition he has continued to curate it: updating code samples to work with the latest version of Ruby, enabling syntax highlighting, converting it to use Markdown, and more.
Similarly Mark Pilgrim’s Dive Into HTML 5 and Dive Into Python 3 were assembled from copies and re-deployed to the Web. Prior to his departure Pilgrim used Github to manage the content for his books. Github is a distributed revision control system, where everyone working with the code has a full copy of it local on their machine. So rather than needing to get content out of the Internet Archive, developers created the diveintomark organization account on Github, and pushed their clones of the original repositories there.
Much of Why and Pilgrim’s code was also developed on GitHub. So even though the master was deleted, many people had clones, and were able to work together to establish a new master. Philip Cromer created the whymirror on Github, which collected _why’s code. Jeremy Ruten created _why’s Estate which is a hypertext archive collects pointers to the various software archives, and writings that have been preserved in Internet Archive and elsewhere.
So, it turns out that the supposedly brittle medium of the Web, where a link can easily break, and a whole website can be capriciously turned off, is a bit more persistent than we think. These events remind me of Matthew Kirschenbaum’s book Mechanisms which deconstructs notions of electronic media being fleeting or impermanent to show how electronic media (especially that which is stored on hard drives) is actually quite resilient and resistent to change. Mechanisms contains a fascinating study of how William Gibson’s poem Agrippa (which was engineered to encrypt itself and become unreadable after a single reading) saw new life on the Internet, as it was copied around on FTP, USENET, email listservs, and ultimately the Web:
Agrippa owes its transmission and continuing availability to a complex network of individuals, communities, ideologies, markets, technologies, and motives … from its example we can see that the preservation of digital media has a profound social dimension that is at least as important as purely technical considerations. Hacking Agrippa
Small Data
In the forensic spirit of Mechanisms, let’s take a closer look at Web technology, specifically HTML. Remember the first URL and how CERN was able to revive it? When you think about it, it’s kind of amazing that you can still look at that HTML in your modern browser, right? Do you think you could view your 20 year old word processing documents today? Jeff Rothenberg cynically observed
digital information lasts forever—or five years, whichever comes first
Maybe if we focus on the archival sliver instead of the impossibility of everything we’re not doing so bad.
As we saw in the cases of Pilgirm and _why the Internet Archive and other web archiving projects play an important role in snapshotting Web pages. But we are also starting to see social media companies are building tools that allow their users to easily extract or “archive” their content. These tools are using HTML in an interesting new way that is worth taking a closer look at.
How many Facebook users are there here? How many of you have requested your archive? If you navigate to the right place in your settings you can “Download a copy of your Facebook data.” When you click on the button you set in motion a process that gathers together your profile, contact information, wall, photos, synced photos, videos, friends, messages, pokes, events, settings, security and (ahem) ads. This takes Facebook a bit of time, it took a day the last time I tried it, and you get an email when it’s finished which contains a link to download a zip file. The zip file contains HTML, JPEG, MP4 files which you can open in your browser. You don’t need to be connected to the Internet, everything is available locally.
Similarly Twitter allow you to request an archive periodically, which triggers an email when it is ready for you to pick up. Much like the Facebook archive it is delivered as a zip file, which contains an easily browsable HTML package. The Twitter archive is actually more like a dynamic application, since it includes a JavaScript application called Grailbird. Grailbird lets you search your tweets, and examine tweets from different time periods. Just like the Facebook archive everything Grailbird needs is available locally, and the application will work when you are disconnected from the Internet. Although user’s avatar thumbnail images are still loaded directly from the Web. But all your tweet data is available as JavaScript and CSV. The application depends on some popular JavaScript libraries like jQuery and Underscore, but those also are bundled right with the archive. It would be nice to see Twitter release Grailbird as a project on Github as many of their other software projects are. Thinking of Grailbird as a visualization framework for tweets would allow interested parties to add new visualizations (e.g. tweets on a map, network graphs, etc). You could also imagine tools for reaching out into the network of an individual’s tweets to fetch tweets that they were replying to, and persisting them back locally to the package.
Some of you may remember that the Data Liberation Front (led by Brian Fitzpatrick at Google) and the eventual product offering Google Takeout were early innovators in this area. Google Takeout allows you to download data from 14 of their products as a zip file. The service isn’t without criticism, because it doesn’t include things like your Gmail archive or your search history. The contents of the archive are also somewhat more difficult to work with, compared to the Facebook and Twitter equivalents. For example, each Google+ update is represented as a single HTML file, and there isn’t a notion of a minimal, static application that you can use to browse them. The HTML also references content out on the Web, and isn’t as self-contained as Twitter and Facebook’s archive. But having snapshots of your Youtube videos, and contents of your Google Drive is extremely handy. As Brad Fitzpatrick wrote in 2010, Google Takeout is kind of a remarkable achievement, or realization for a big publicly traded behometh to make:
Locking your users in, of course, has the advantage of making it harder for them to leave you for a competitor. Likewise, if your competitors lock their users in, it is harder for those users to move to your product. Nonetheless, it is far preferable to spend your engineering effort on innovation than it is to build bigger walls and stronger doors that prevent users from leaving. Making it easier for users to experiment today greatly increases their trust in you, and they are more likely to return to your product line tomorrow.
I mention Facebook, Twitter and Google here because I think these archiving services are important for memory institutions like museums, libraries and archives. They allow individuals to download their data from the huge corpus that is available–a sliver of a sliver of a sliver. When a writer or politician donates their papers, what if we accessioned their Facebook or Twitter archive? Dave Winer for example has started collecting Twitter archives that have been donated to him, that meet a certain criteria, and making them public. If we have decided to add someone’s papers to a collection, why not acquire their social media archives and store them along with their other born digital and traditional content? Yes, Twitter (as a whole) is being archived by the Library of Congress, as so called big data. But why don’t we consider these personal archives as small data, where context and original order are preserved with other relevant material in a highly usable way? As Rufus Pollock of the Open Knowledge Foundation said
This next decade belongs to distributed models not centralized ones, to collaboration not control, and to small data not big data.
The other interesting thing about these services is their use of HTML as a packaging format. My coworker Chris Adams once remarked that the one format he expects to be able to read in 100 years is HTML. Of course we can’t predict the future. But I suspect he may be right. We need best practices, or really just patterns for creating HTML packages of archival content. We need to make sure our work sits on top of common tools for the Web. We need to support the Web browser, particularly open source ones. We need to track and participate in Web standardization efforts such as the W3C and the WHATWG. We must keep the usability of the archive in mind: is it easy to open up in your browser and wander around in the archive as with the Twitter and Facebook examples? And most importantly, as Johan van der Knijff of the National Library of the Netherlands discusses in his study of EPUB, it is important that all resources are local to the package. Loading images, JavaScript, etc from a remote location makes the archive vulnerable, since it becomes dependent on some part of the Web staying alive. Perhaps we also need tools like ArchiveReady for inspecting local HTML packages (in addition to websites) and reporting on their archivability?
Conclusion
So how to wrap up this strange, fragmented, incomplete tour through Web preservation? I feel like I should say something profound, but I was hoping these stories of the Web would do that for me. I can only say for myself that I want to give back to the Web the way it has given to me. With 25 years behind us the Web needs us more than ever to help care for the archival slivers it contains. I think libraries, museums and archives that realize that they are custodians of the Web, and align their mission with the grain of the Web, will be the ones that survive, and prosper. Brian Fitzpatrick, Jason Scott, Brewster Kahle, Mislav Marohnic, Philip Cromer, Jeremy Ruten and Aaron Swartz demonstrated their willingness to work with the Web as a medium in need of preservation, as well as a medium for doing the preservation. We need more of them. We need to provide spaces for them to do their work. They are the new faces of our profession.