diving into VIAF
Last week saw a big (well big for library data nerds) announcement from OCLC that they are making the data for the Virtual International Authority File (VIAF) available for download under the terms of the Open Data Commons Attribution (ODC-BY) license. If you’re not already familiar with VIAF here’s a brief description from OCLC Research:
Most large libraries maintain lists of names for people, corporations, conferences, and geographic places, as well as lists to control works and other entities. These lists, or authority files, have been developed and maintained in distinctive ways by individual library communities around the world. The differences in how to approach this work become evident as library data from many communities is combined in shared catalogs such as OCLC’s WorldCat.
VIAF’s goal is to make library authority files less expensive to maintain and more generally useful to the library domain and beyond. To achieve this, VIAF seeks to include authoritative names from many libraries into a global service that is available via the Web. By linking disparate names for the same person or organization, VIAF provides a convenient means for a wider community of libraries and other agencies to repurpose bibliographic data produced by libraries serving different language communities
More specifically, the VIAF service: links national and regional-level authority records, creating clusters of related records and expands the concept of universal bibliographic control by:
- allowing national and regional variations in authorized form to coexist
- supporting needs for variations in preferred language, script and spelling
- playing a role in the emerging Semantic Web
If you went and looked at the OCLC Research page you’ll notice that last month the VIAF project moved to OCLC. This is evidence of a growing commitment on OCLC’s part to make VIAF part of the library information landscape. It currently includes data about people, places and organizations from 22 different national libraries and other organizations.
Already there has been some great writing about what the release of VIAF data means for the cultural heritage sector. In particular Thom Hickey’s Outgoing is a trove of information about the project, which provides a behind-the-scense look at the various services it offers.
Rather than paraphrase what others have said already I thought I would download some of the data and report on what it looks like. Specifically I’m interested in the RDF data (as opposed to the custom XML, and MARC variants) since I believe it to have the most explicit structure and relations. The shared semantics in the RDF vocabularies that are used also make it the most interesting from a Linked Data perspective.
Diving In
The primary data structure of interest in the data dumps that OCLC has made available is what they call the cluster. A cluster is essentially a hub-and-spoke model with a resource for the person, place or organization in the middle that is attached via the spokes to conceptual resources at the participating VIAF institutions. As an example here is an illustration of the VIAF cluster for the Canadian archivist Hugh Taylor
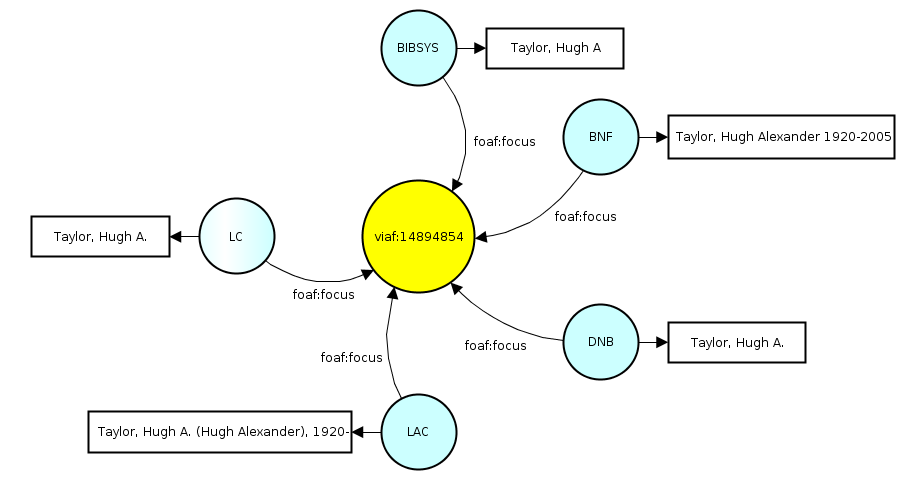
Here you can see a FOAF Person resource (yellow) in the middle that is linked to from SKOS Concepts (blue) for Bibliothèque nationale de France, The Libraries and Archives of Canada, Deutschen Nationalbibliothek, BIBSYS (Norway) and the Library of Congress. Each of the SKOS Concepts have their own preferred label, which you can see varies across institution. This high level view obscures quite a bit of data, which is probably best viewed in Turtle if you want to see it:
<http://viaf.org/viaf/14894854>
rdaGr2:dateOfBirth "1920-01-22" ;
rdaGr2:dateOfDeath "2005-09-11" ;
a rdaEnt:Person, foaf:Person ;
owl:sameAs <http://d-nb.info/gnd/109337093> ;
foaf:name "Taylor, Hugh A.", "Taylor, Hugh A. (Hugh Alexander), 1920-", "Taylor, Hugh Alexander 1920-2005" .
<http://viaf.org/viaf/sourceID/BIBSYS%7Cx90575046#skos:Concept>
a skos:Concept ;
skos:inScheme <http://viaf.org/authorityScheme/BIBSYS> ;
skos:prefLabel "Taylor, Hugh A." ;
foaf:focus <http://viaf.org/viaf/14894854> .
<http://viaf.org/viaf/sourceID/BNF%7C12688277#skos:Concept>
a skos:Concept ;
skos:inScheme <http://viaf.org/authorityScheme/BNF> ;
skos:prefLabel "Taylor, Hugh Alexander 1920-2005" ;
foaf:focus <http://viaf.org/viaf/14894854> .
<http://viaf.org/viaf/sourceID/DNB%7C109337093#skos:Concept>
a skos:Concept ;
skos:inScheme <http://viaf.org/authorityScheme/DNB> ;
skos:prefLabel "Taylor, Hugh A." ;
foaf:focus <http://viaf.org/viaf/14894854> .
<http://viaf.org/viaf/sourceID/LAC%7C0013G3497#skos:Concept>
a skos:Concept ;
skos:inScheme <http://viaf.org/authorityScheme/LAC> ;
skos:prefLabel "Taylor, Hugh A. (Hugh Alexander), 1920-" ;
foaf:focus <http://viaf.org/viaf/14894854> .
<http://viaf.org/viaf/sourceID/LC%7Cn++82148845#skos:Concept>
a skos:Concept ;
skos:exactMatch <http://id.loc.gov/authorities/names/n82148845> ;
skos:inScheme <http://viaf.org/authorityScheme/LC> ;
skos:prefLabel "Taylor, Hugh A." ;
foaf:focus <http://viaf.org/viaf/14894854> .
The Numbers
The RDF Cluster Dataset http://viaf.org/viaf/data/viaf-20120422-clusters.xml.gz is 2.1G gzip compressed RDF data. Rather than it being one complete RDF/XML file, each line has a complete RDF/XML document on it, which represents a single cluster. All in all there are 20,379,541 clusters in the file.
I quickly hacked together a rdflib filter that reads the uncompressed line-oriented RDF/XML and writes the RDF as ntriples:
import sys
import rdflib
for line in sys.stdin:
g = rdflib.Graph()
g.parse(data=line)
print g.serialize(format='nt').encode('utf-8'),
This took 4 days to run on my (admittedly old) laptop. If you are interested in seeing the ntriples let me know and I can see about making it available somewhere. It is 2.8G gzip compressed. An ntriples dump might be a useful version of the RDF data for OCLC to make available, since it would be easier to load into triplestores, and otherwise muck around with (more on that below) than the line oriented RDF/XML. I don’t know much about the backend that drives VIAF (has anyone seen it written up?)…but I would understand if someone said it was too expensive to generate, and was intentionally left as an exercise for the downloader.
Given its line-oriented nature, ntriples is very handy for doing analysis from the Unix command line with cut, sort, uniq, etc. From the ntriples file I learned that the VIAF RDF dump is made up of 377,194,224 assertions or RDF triples. Here’s the breakdown on the types of resources present in the data:
| Resource Type | Number of Resources |
|---|---|
| skos:Concept | 26,745,286 |
| foaf:Document | 20,379,541 |
| foaf:Person | 15,043,112 |
| rda:Person | 15,043,112 |
| foaf:Organization | 3,722,318 |
| foaf:CorporateBody | 3,722,318 |
| dbpedia:Place | 195,472 |
Here’s a breakdown of predicates (RDF properties) that are used:
| RDF Property | Number of Assertions |
|---|---|
| rdf:type | 84,851,159 |
| foaf:focus | 45,510,716 |
| foaf:name | 44,729,247 |
| rdfs:comment | 41,253,178 |
| owl:sameAs | 32,741,138 |
| skos:prefLabel | 26,745,286 |
| skos:inScheme | 26,745,286 |
| foaf:primaryTopic | 20,379,541 |
| void:inDataset | 20,379,541 |
| skos:altLabel | 16,702,081 |
| skos:exactMatch | 8,487,197 |
| rda:dateOfBirth | 5,215,150 |
| rda:dateOfDeath | 1,364,355 |
| owl:differentFrom | 1,045,172 |
| rdfs:seeAlso | 1,045,172 |
I’m expecting these statistics to be useful in helping target some future work I want to do with the VIAF RDF dataset (to explore what an idiomatic JSON representation for the dataset would be, shhh). In addition to the RDF, OCLC also makes a dump of link data available. It is a smaller file (239M gzip compressed) of tab delimited data, which looks like:
... http://viaf.org/viaf/10014828 SELIBR:219751 http://viaf.org/viaf/10014828 SUDOC:052584895 http://viaf.org/viaf/10014828 NKC:xx0015094 http://viaf.org/viaf/10014828 BIBSYS:x98003783 http://viaf.org/viaf/10014828 LC:24893 http://viaf.org/viaf/10014828 NUKAT:vtls000425208 http://viaf.org/viaf/10014828 BNE:XX917469 http://viaf.org/viaf/10014828 DNB:121888096 http://viaf.org/viaf/10014828 BNF:http://catalogue.bnf.fr/ark:/12148/cb13566121c http://viaf.org/viaf/10014828 http://en.wikipedia.org/wiki/Liza_Marklund ...
There are 27,046,631 links in total. With a little more Unix commandline-fu I was able to get some stats on the number of links by institution:
| Institution | Number of Links |
|---|---|
| LC NACO (United States) | 8,325,352 |
| Deutschen Nationalbibliothek (Germany) | 7,732,546 |
| SUDOC (France) | 2,031,452 |
| BIBSYS (Norway) | 1,822,681 |
| Bibliothèque nationale de France | 1,643,068 |
| National Library of Australia | 977,141 |
| NUKAT Center (Poland) | 894,981 |
| Libraries and Archives of Canada | 674,088 |
| National Library of the Czech Republic | 598,848 |
| Biblioteca Nacional de España | 519,511 |
| National Library of Israel | 327,455 |
| Biblioteca Nacional de Portugal | 321,064 |
| English Wikipedia | 301,345 |
| Vatican Library | 247,574 |
| Getty Union List of Artist Names | 202,711 |
| National Library of Sweden | 161,845 |
| RERO (Switzerland) | 119,366 |
| Istituto Centrale per il Catalogo Unico (Italy) | 45,208 |
| Swiss National Library | 33,866 |
| National Széchényi Library (Hungary) | 33,727 |
| Bibliotheca Alexandrina (Egypt) | 26,877 |
| Flemish Public Libraries | 4,819 |
| Russian State Library | 997 |
| Extended VIAF Authority | 109 |
The 301,345 links to Wikipedia are really great to see. It might be a fun project to see how many of these links are actually present in Wikipedia, and if they can be automatically added with a bot if they are missing. I think it’s useful to have the HTTP identifier in the link dump file, as is the case for the BNF identifiers. I’m not sure why the DNB, Sweden, and LC URLs aren’t expressed URLs as well.
One other parting observation (I’m sure I’ll blog more about this) is that it would be nice if more of the data that you see in the HTML presentation were available in the RDF dumps. Specifically, it would be useful to have the Wikipedia links expressed in the RDF data, as well as linked works (uniform titles).
Anyway, a big thanks to OCLC for making the VIAF dataset available! It really feels like a major sea change in the cultural heritage data ecosystem.