JavaScript and Archives
Tantek Çelik has some strong words about the use of JavaScript in Web publishing, specifically regarding it’s accessibility and longevity:
… in 10 years nothing you built today that depends on JS for the content will be available, visible, or archived anywhere on the web
It is a dire warning. It sounds and feels true. I am in the middle of writing a webapp that happens to use React, so Tantek’s words are particularly sobering.
And yet, consider for a moment how Twitter make personal downloadable archives available. When you request your archive you eventually get a zip file. When you unzip it, you open an index.html file in your browser, and are provided you with a view of all the tweets you’ve ever sent.
If you take a look under the covers you’ll see it is actually a JavaScript application called Grailbird. If you have JavaScript turned on it looks something like this:
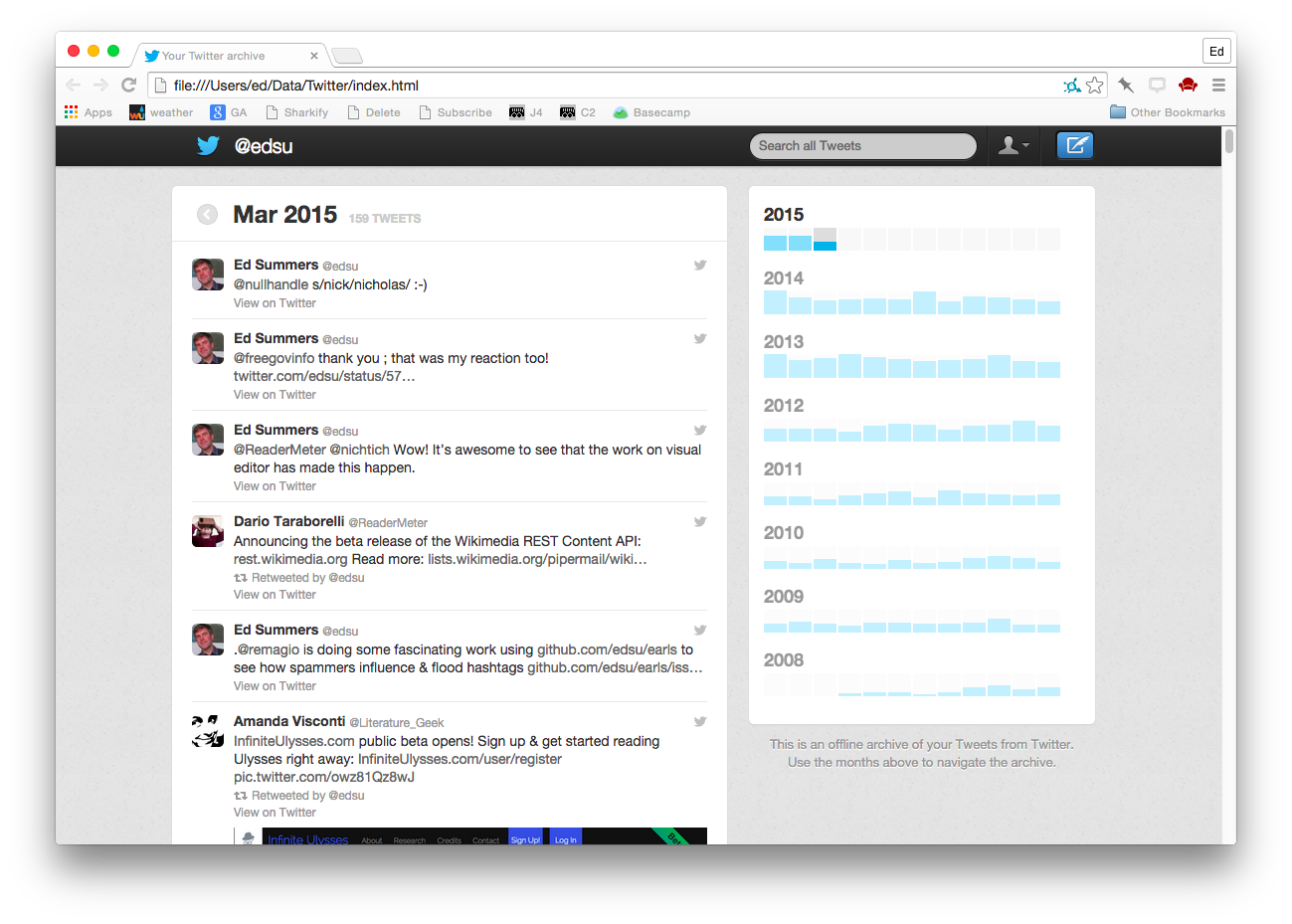
If you have JavaScript turned off it looks something like this:
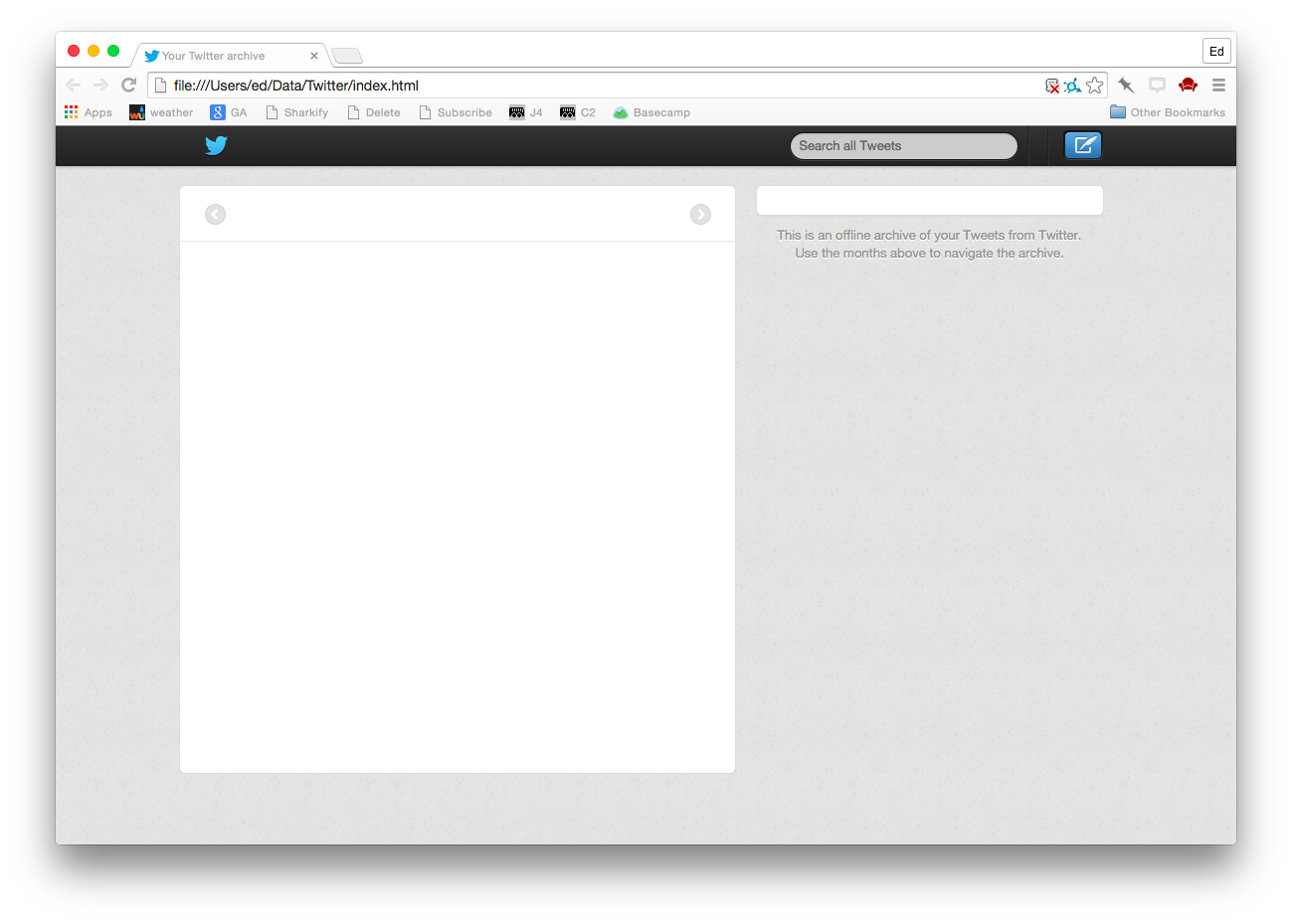
But remember this is a static site. There is no server side piece. Everything is happening in your browser. You can disconnect from the Internet and as long as your browser has JavaScript turned on it is fully functional. (Well the avatar URLs break, but that could be fixed). You can search across your tweets. You can drill into particular time periods. You can view your account summary. It feels pretty durable. I could stash it away on a hard drive somewhere, and come back in 10 years and (assuming there are still web browsers with a working JavaScript runtime) I could still look at it right?
So is Tantek right about JavaScript being at odds with preservation of Web content? I think he is, but I also think JavaScript can be used in the service of archiving, and that there are starting to be some options out there that make archiving JavaScript heavy websites possible.
The real problem that Tantek is talking about is when human readable content isn’t available in the HTML and is getting loaded dynamically from Web APIs using JavaScript. This started to get popular back in 2005 when Jesse James Garrett coined the term AJAX for building app-like web pages using asynchronous requests for XML, which is now mostly JSON. The scene has since exploded with all sorts of client side JavaScript frameworks for building web applications as opposed to web pages.
So if someone (e.g. Internet Archive) comes along and tries to archive a URL it will get the HTML and associated images, stylesheets and JavaScript files that are referenced in that HTML. These will get saved just fine. But when the content is played back later in (e.g. Wayback Machine) the JavaScript will run and try to talk to these external Web APIs to load content. If those APIs no longer exist, the content won’t load.
One solution to this problem is for the web archiving process to execute the JavaScript and to archive any of the dynamic content that was retrieved. This can be done using headless browsers like PhantomJS, and supposedly Google has started executing JavaScript. Like Tantek I’m dubious about how widely they execute JavaScript. I’ve had trouble getting Google to index a JavaScript heavy site that I’ve inherited at work. But even if the crawler does execute the JavaScript, user interactions can cause different content to load. So does the bot start clicking around in the application to get content to load? This is yet more work for a archiving bot to do, and could potentially result in write operations which might not be great.
Another option is to change or at least augment the current web archiving paradigm by adding curator driven web archiving to the mix. The best examples I’ve seen of this are Ilya Kreymer’s work on pywb and pywb-recorder. Ilya is a former Internet Archive engineer, and is well aware of the limitations in the most common forms of web archiving today. pywb is a new player for web archives and pywb-recorder is a new recording environment. Both work in concert to let archivists interactively select web content that needs to be archived, and then for that content to be played back. The best example of this is his demo service webrecorder.io which composes pywb and pywb-recorder so that anyone can create a web archive of a highly dynamic website, download the WARC archive file, and then reupload it for playback.
The nice thing about Ilya’s work is that it is geared at archiving this JavaScript heavy content. Rhizome and the New Museum in New York City have started working with Ilya to use pywb to archive highly dynamic Web content. I think this represents a possible bright future for archives, where curators or archivists are more part of the equation, and where Web archives are more distributed, not just at Internet Archive and some major national libraries. I think the work Genius are doing to annotate the Web, archived versions of the Web is in a similar space. It’s exciting times for Web archiving. You know, exciting if you happen to be an archivist and/or archiving things.
At any rate, getting back to Tantek’s point about JavaScript. If you are in the business of building archives on the Web definitely think twice about using client side JavaScript frameworks. If you do, make sure your site degrades so that the majority of the content is still available. You want to make it easy for Internet Archive to archive your content (lots of copies keeps stuff safe) and you want to make it easy for Google et al to index it, so people looking for your content can actually find it. Stanford University’s Web Archiving team have a super set of pages describing archivability of websites. We can’t control how other people publish on the Web, but I think as archivists we have a responsibility to think about these issues as we create archives on the Web.