t.co
People are discovering that Twitter’s archive
download includes shortened t.co URLs instead of the
original URLs that you tweeted. If (when) Twitter goes away, the server
at t.co won’t be available to respond to requests. This
means your archived tweets will potentially lack some pretty significant
context. Even if they don’t work (404) these original URLs are
important, because you can at least try to look them up in a web archive
like the Internet Archive.
It’s kind of strange that Twitter’s archive download doesn’t display
the original URL because some (not all) of the t.co URLs,
and their “expanded” form are present in the archived data. The client
side app just doesn’t use them in the display. On the other hand maybe
it isn’t so strange, since Twitter is in the surveillance capitalism
business, and clicks are what corporate social media companies crave
most.
Tim Hutton has written a handy
tool that will rewrite your archive as a set of Markdown files, and
which also uses the longer URLs that are available. I think this is
super useful, but I actually really quite like the little client-side
application that Twitter provided. So I wanted something that would
rewrite the t.co URLs to show the original URL instead.

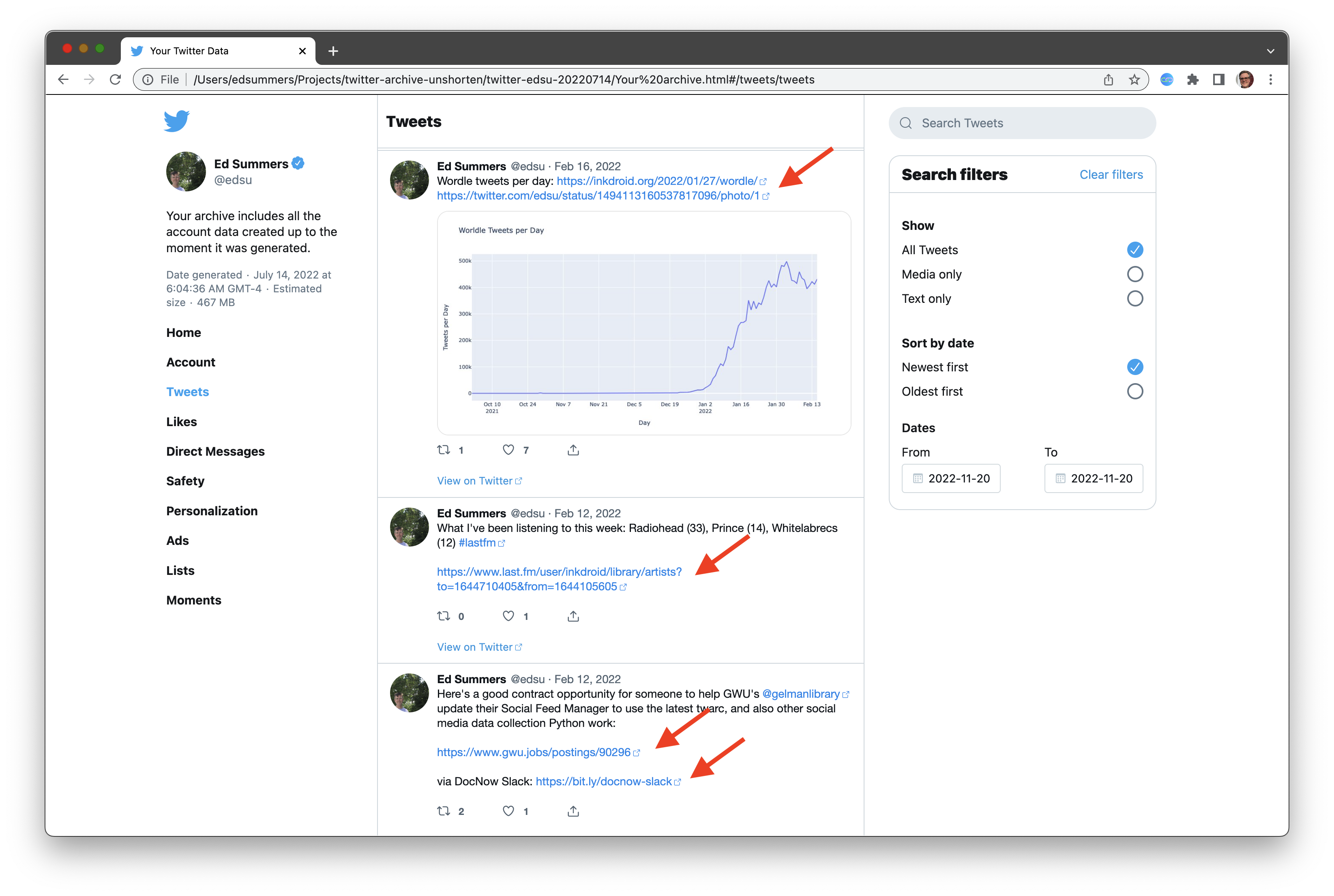
twitter-archive-unshorten
is a small Python program that will examine all the JavaScript files in
the archive download and rewrite the t.co short URLs to
their original full URL form.
If you look closely one thing you may notice in the screenshots above
is that other short URLs (e.g. bit.ly) are not unshortened.
I didn’t want this program to completely unravel the short URLs since
all kinds of things can go wrong when trying to resolve these. I figure
if I included a bit.ly URL in my tweet it seems like that’s
what the archive should show?
If you want to try it out make sure you have Python3 installed then:
- Make a backup of your original Twitter archive!
pip3 install twitter-archive-unshorten- Unzip your Twitter archive zip file
twitter-archive-unshorten /path/to/your/archive/directory/
It might take a while, depending on how many tweets with URLs you
have. I had 20,000 or so short URLs so it took a 2-3 hours. Once it’s
finished you should be able open your Archive and interact with it
without seeing the t.co URLs. The mapping of short URLs to
long URLs that was discovered is saved in your archive directory as
data/shorturls.json in case you need it. There also should
be a twitter-archive-unshorten.log file in the root of the
archive, with a record of what was done.
Random aside. One interesting thing I discovered when creating this program is that there are some very short t.co URLs, for example: https://t.co/L. I also learned from Hank that somehow https://t.co/elon was (recently?) created.