Save WACZ Now
I was fortunate to be able participate in a Project Stand workshop with the University of Maryland this past weekend. We spent the morning discussing web archiving practices in the context of student activism. During the conversation Zakiya Collier mentioned that she noticed that the Internet Archive’s SavePageNow service now has the ability to export Web Archive as Collection Zipped or WACZ files. This was news to me, and seems like a pretty new addition?
Previously when you saved web content with SavePageNow the content was added to the huge, and ever expanding public collection of web content that is available in the Internet Archive’s Wayback Machine. A WACZ download gives users the option of also having a copy of the archived data as well. This means you can build your own local collections of web archives, and potentially embed web archives on a website of your choosing using Webrecorder’s ReplayWebPage JavaScript component.
So I wanted to take it for a spin, and as an experiment I tried archiving this NYTimes article.
First I went to https://web.archive.org/save/, entered the URL for the NYTimes article, and selected to “Email me a WACZ file”. If you don’t see this option you will need to create an account with Internet Archive and log in. I also selected to “Save outlinks” which tells SPN to save not just the article, but any page that the article links to (which can be pretty handy for archiving the context of a web page).
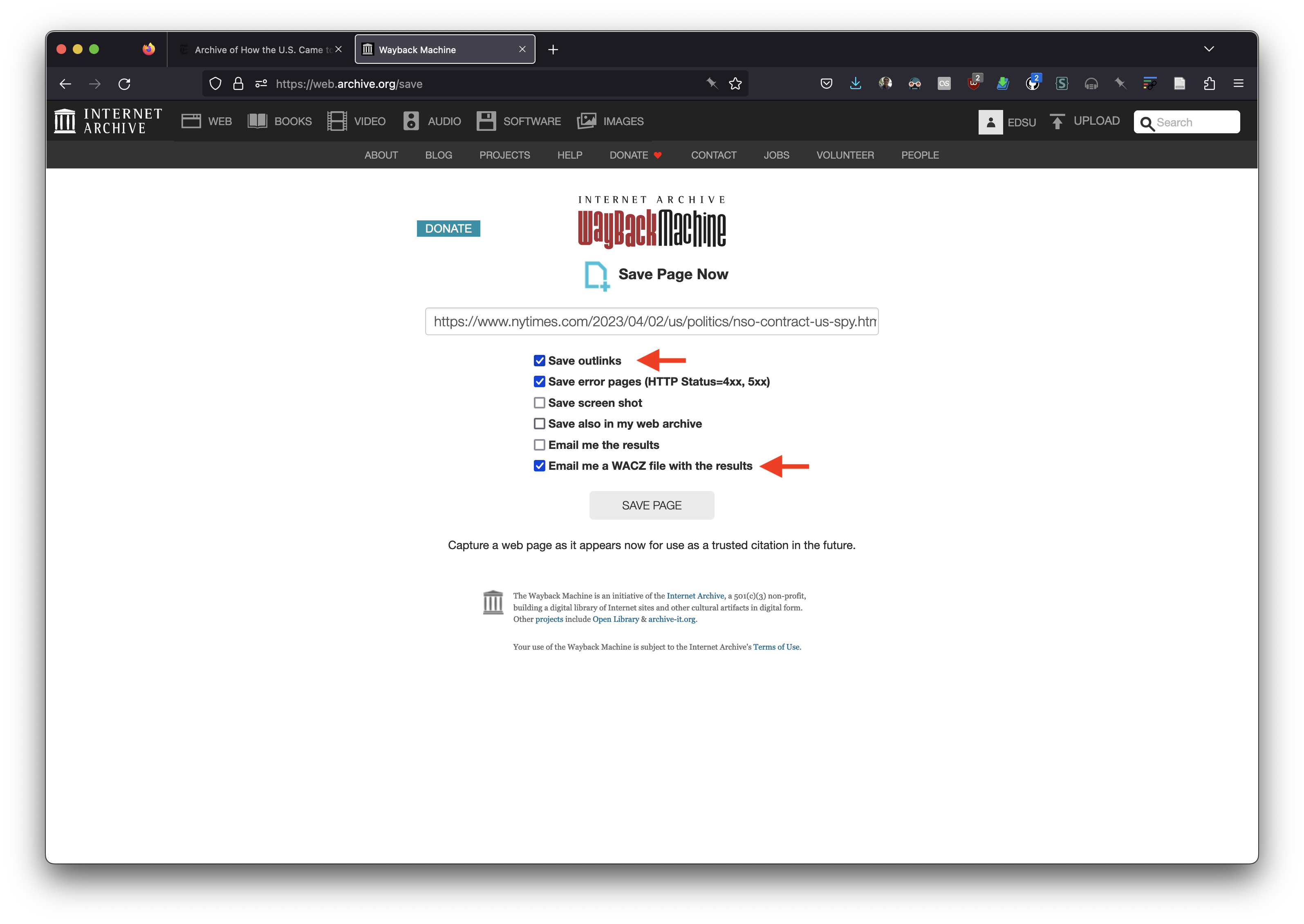
A few minutes later I received an email which told me that the WACZ was available at
and that I should download it, because it would only be there for three days. If you see this post in time you can probably download it too since there doesn’t appear to be any authentication involved.
After downloading I headed over to Webrecorder’s ReplayWebPage, which is a client side web application for viewing WACZ’s locally. You can also use their ArchiveWebpage to read and write WACZ files (more on that below). But I tend to use ReplayWebPage for viewing WACZ files since I use Firefox and ArchiveWebPage is Chrome only (well Chromium, so Brave and some others too).
Once loaded it up I saw the list of pages that were archived (remember I selected to “Save outlinks”):
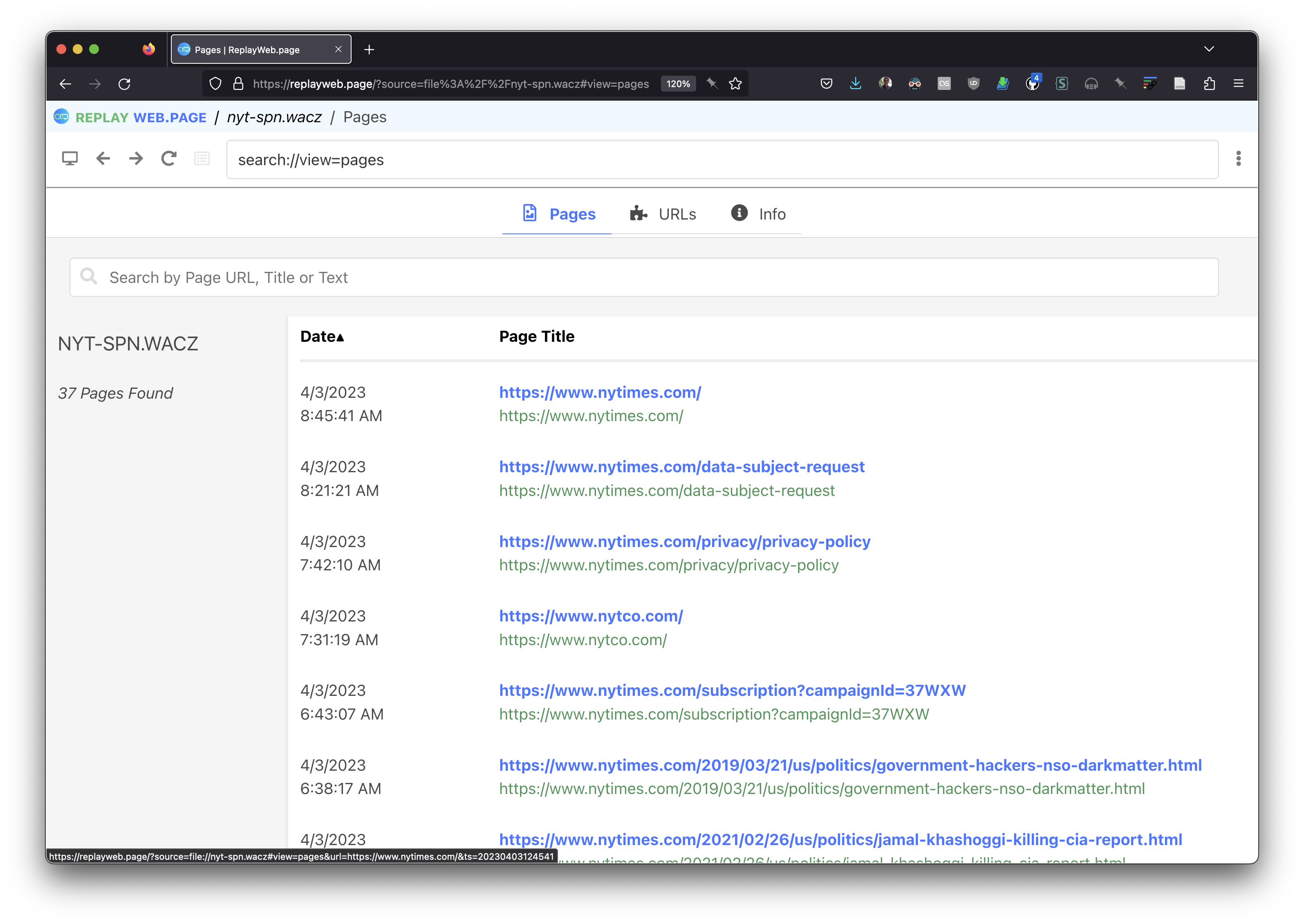
And from there I was able to find the page I archived:
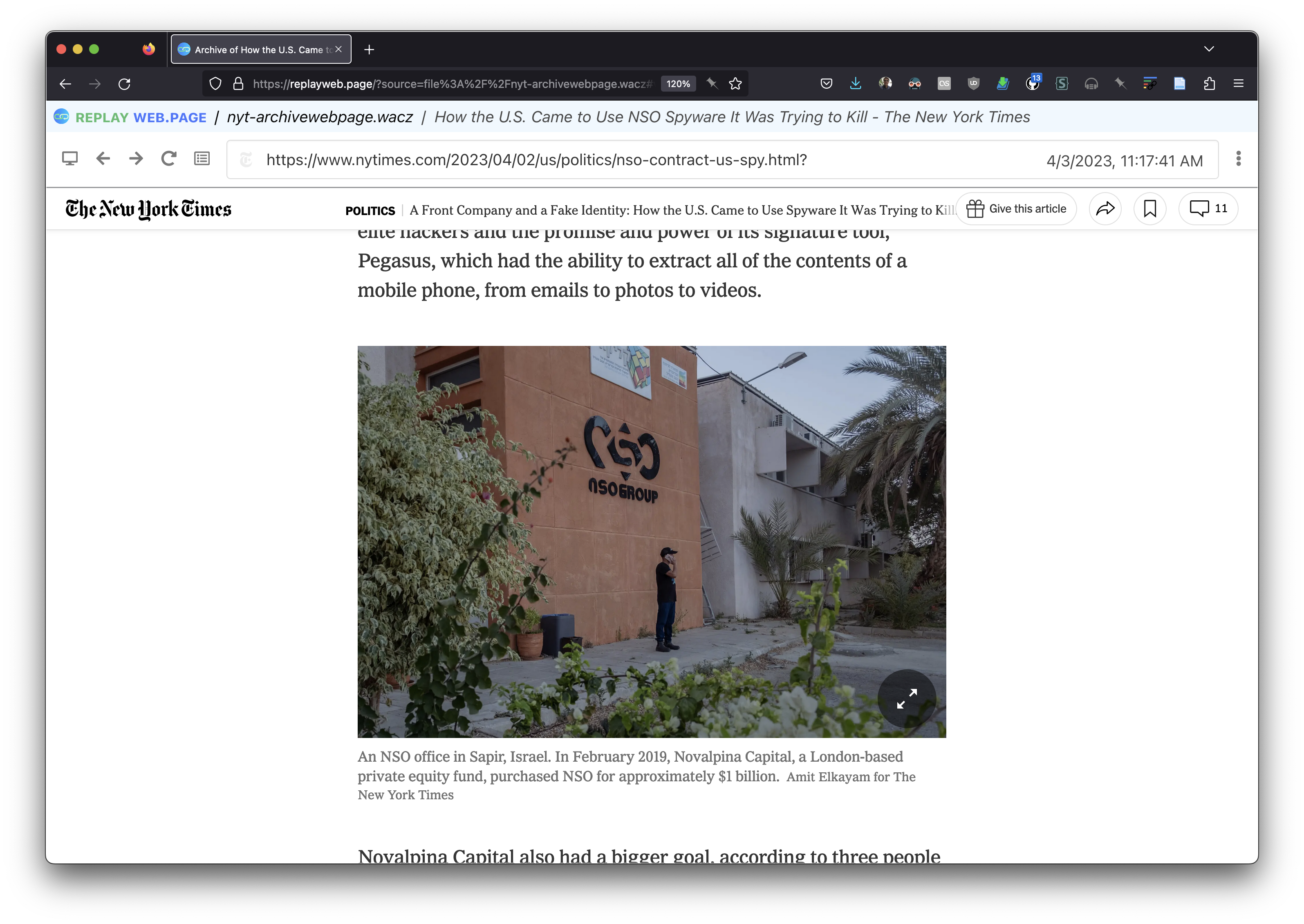
As I scrolled down I noticed an photograph of the NSO Office in Sapir failed to render.

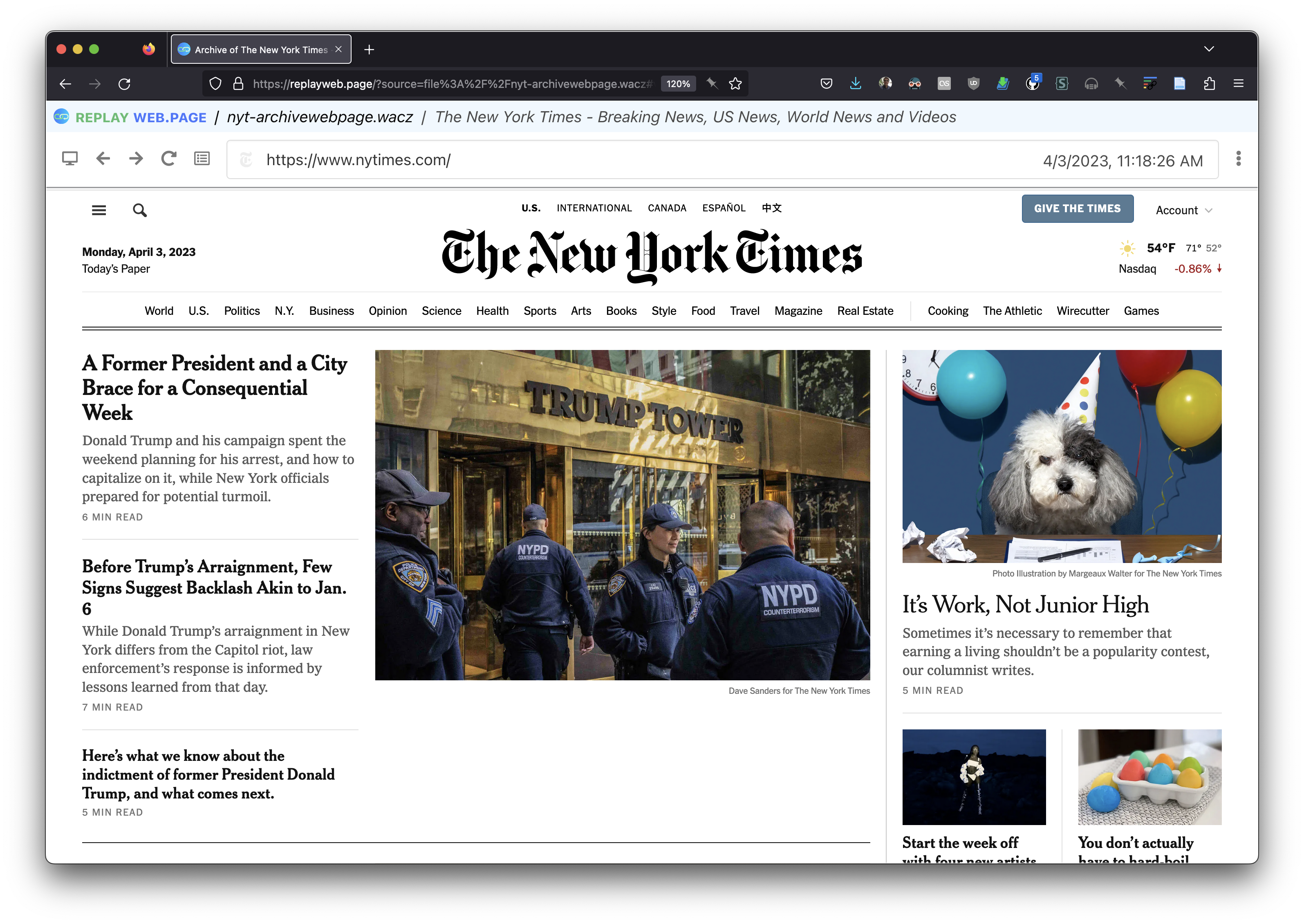
In fact all the inline images seemed to be missing. Since the NYTimes homepage was archived as an outlink I clicked to look at that, and noticed that several images failed to render there too:

This prompted me to create an archive with ArchiveWebPage to compare the results. You do need to use Chrome, and install the plugin. After that I navigated to the NYTimes article and clicked to start “recording”. ArchiveWebPage collects web content (HTTP requests and responses) as a result of browsing. It currently doesn’t let you collect all the links on a page like SavePageNow. But you can click on whatever you want to add to the archive. So I added the NYTimes homepage as well for comparison.
While it’s possible to view your local archives in ArchiveWebPage itself, I decided to export the archive as a WACZ and then imported it into ReplayWebPage so I could compare. Once loaded the list of captured pages is a lot shorter, because it only recorded the two pages I viewed.
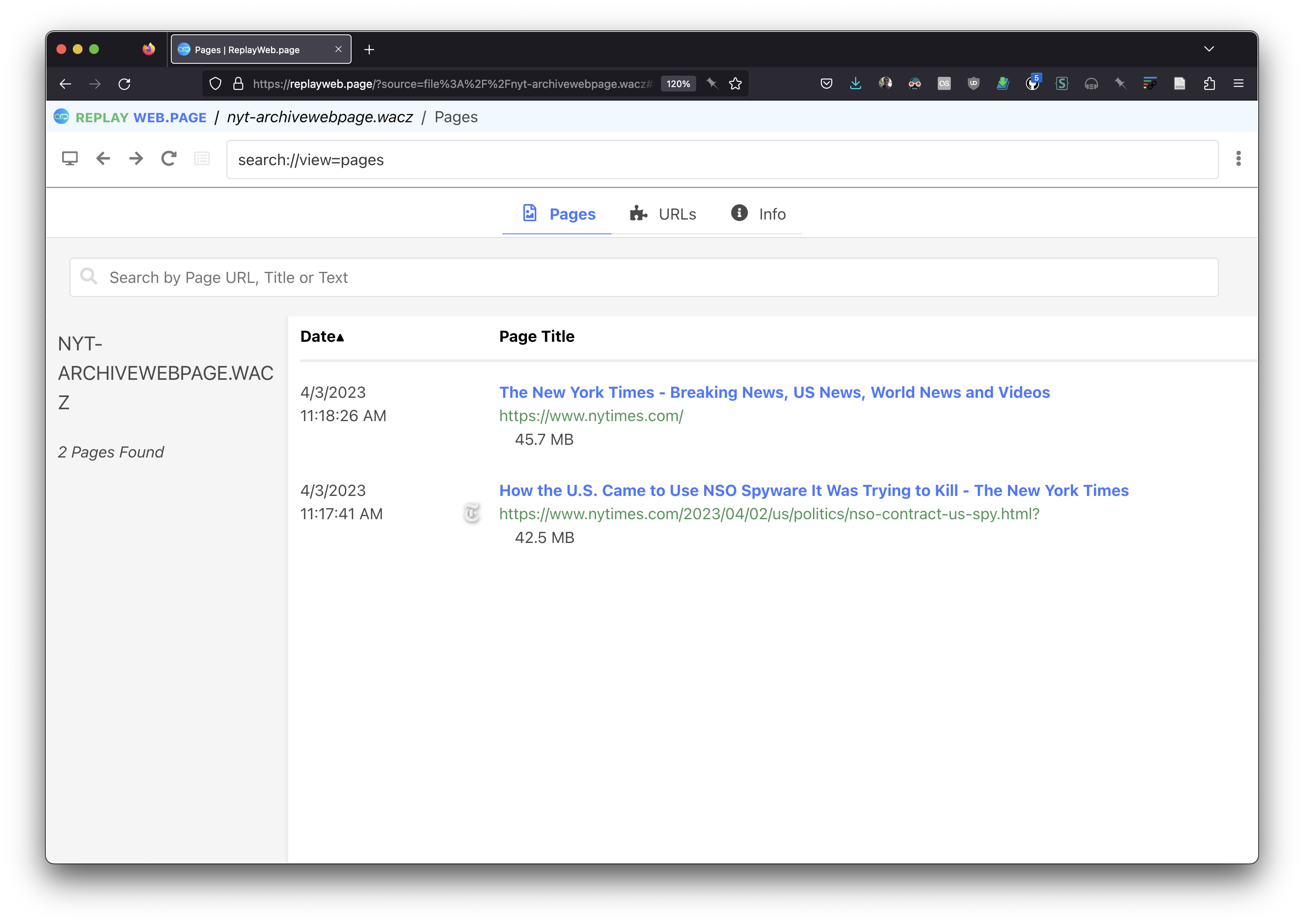
You can see the article itself looked similar.
But the image that was previously unavailable works now!
Also, the images on the NYTimes homepage render, although the primary one appears to be different when I recorded the second time:
Show me the Metadata
One nice thing about WACZ files is that they are really just ZIP files, which you can unzip and inspect.
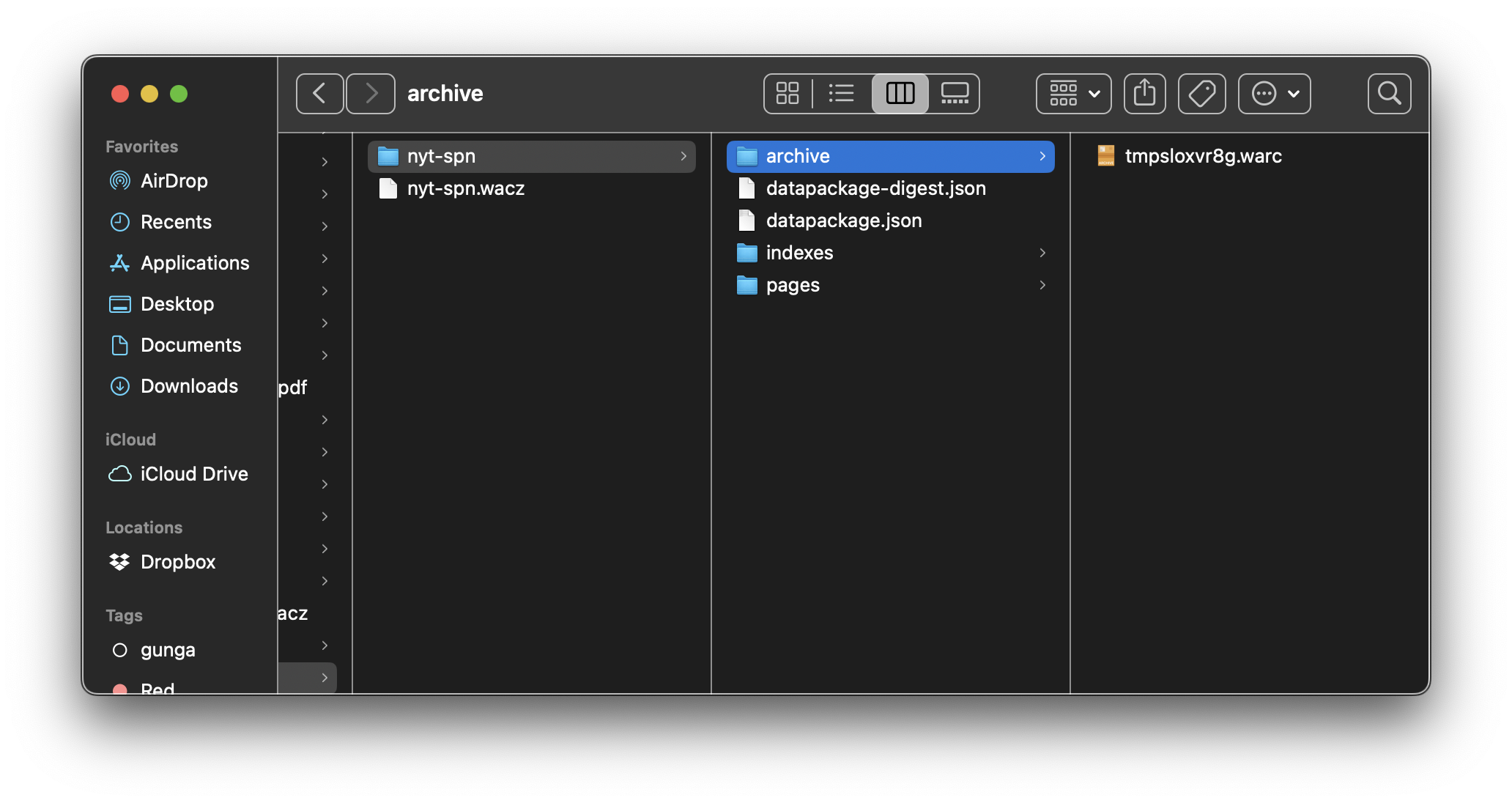
The archive directory contains the WARC (ISO 28500:2017) data from the actual crawl. Looking closer at this one I was interested to find that while it contained 676 response records (HTTP responses from nytimes.com and elsewhere) the request records are not present. So we can’t see how the request was made, what User-Agent was used, etc.
You can also look at the datapackage.json which contains metadata about the crawl, including fixity values for the package files and information about who created the archive. It seems like Internet Archive are using Webrecorder’s [py-wacz] to package up the WARC data that SPN collects. But SavePageNow itself isn’t identified.
{
"profile": "data-package",
"resources": [
{
"name": "index.cdx.gz",
"path": "indexes/index.cdx.gz",
"hash": "sha256:2a143110c5d9a267c301f23e14b5ca9bdf100a3cf7b13e767cd5a2731d516778",
"bytes": 81076
},
{
"name": "index.idx",
"path": "indexes/index.idx",
"hash": "sha256:056eccdfa55648438e90a1a9f18a8e477d95f72bfc7f7fc18c656309268aacb5",
"bytes": 263
},
{
"name": "tmpsloxvr8g.warc",
"path": "archive/tmpsloxvr8g.warc",
"hash": "sha256:fe244db3f22552288fdaaa6801c4507e4a9e4f01412ff9649be06f318c5d87dd",
"bytes": 94449063
},
{
"name": "pages.jsonl",
"path": "pages/pages.jsonl",
"hash": "sha256:5aea8dd6d94c02d6347da2dec8c127e61ec532fd8c851e11fbcfffe091377e3f",
"bytes": 8129
}
],
"created": "2023-04-03T14:06:34Z",
"wacz_version": "1.1.1",
"software": "py-wacz 0.4.8"
}I think there’s also an opportunity for Internet Archive to sign their WACZ files so people can prove that they were really created by the Internet Archive. This could be quite useful for evidentiary purposes.
In Summary
So what did I learn here?
- It’s 🦄✨🎉🎁 to be able to download your data from SavePageNow. It means you can build your own local web archive collections that can exist separately from the Internet Archive. As an example you can see I’m hosting the SavePageNow WACZ and ArchiveWebPage WACZ here on my static website using Webrecorder’s web-replay-gen static site generator.
- I don’t think you have the option of not adding the collected web content to the public Wayback Machine, where it will be accessible in perpetuity (or as long as archive.org is online and functioning as it does now). This might be an issue for you depending on what you are collecting.
- The fidelity of web archives may be an important factor, so do examine the collected data. You may want to compare with what you see with other tools like ArchiveWebPage, browsertrix-crawler and Webrecorder’s new (open source) Browsertrix Cloud service. It would be interesting to investigate if the missing images are actually in the WACZ and failing to play back, or if they are not part of the archive.
- ArchiveWebPage requires more time in terms of browsing if you want to collect all the outlinks on a page. It currently takes more time to navigate to all the pages you want to collect and SavePageNow’s outlinks option simplifies this process. In principle this may not be a bad thing since it requires the person archiving to think through what they are archiving, which was a big theme in the Project Stand workshop. It might also be a potential behavior to add to ArchiveWebPage to be able to easily collect outlinks on a page?
- The Internet Archive’s WACZ file doesn’t contain metadata that identifies it as having come from Internet Archive, which would be quite nice to have. It also doesn’t include contextual information of how the content was archived since the HTTP requests are not present.
All in all I think it’s an exciting development for web archives, and a major milestone for the WACZ as an evolving standard.
Update 2023-04-11
I heard from Vangelis Banos in Internet Archive Slack that the SPN
export now includes a datapackage.json that contains a
title and description that identifies the
archive as originating at the Internet Archive, e.g.
{
"title": "Created using Wayback Machine's Save Page Now.",
"description": "The Wayback Machine is an initiative of the Internet Archive, a 501(c)(3) non-profit, building a digital library of Internet sites and other cultural artifacts in digital form.",
"created": "2023-04-11T16:58:15Z",
"wacz_version": "1.1.1",
"software": "py-wacz 0.4.8"
...
}Combined with the datapackage-digest.json this means you
can verify that archive is claimed to have been from the Internet
Archive and it hasn’t been tampered with. The next step would be to sign the WACZ
so someone could verify that not only is the archive intact, but that it
definitely came from archive.org.